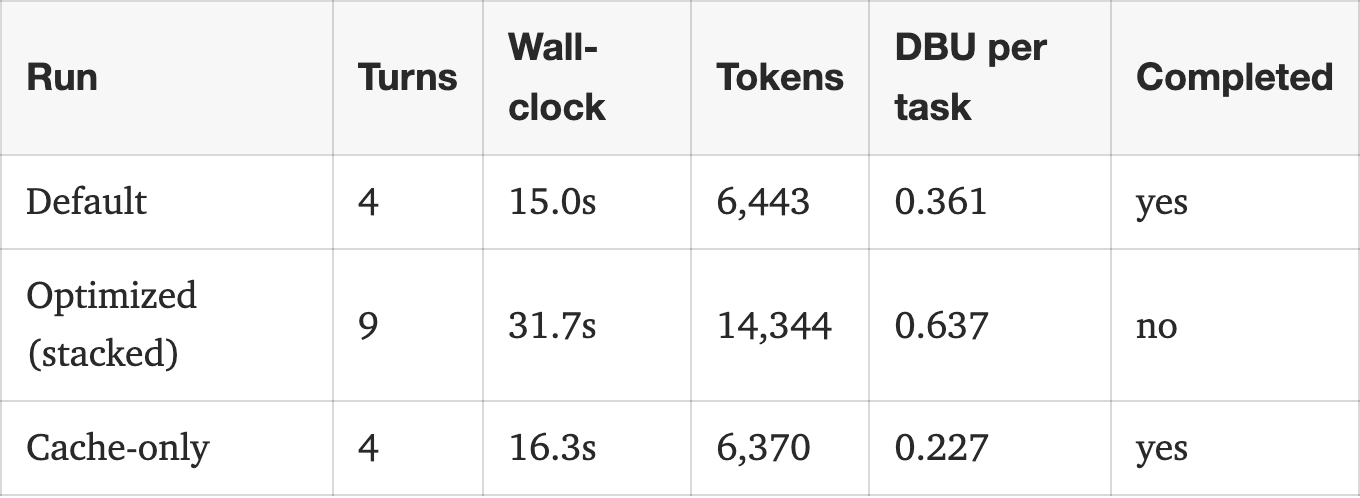
作者探讨了在大型语言模型中优化 token 使用量的方法,特别是在 Databricks 环境中。他们发现,虽然结合三种节省 token 的模式最初使 token 消耗量翻倍,但实施缓存策略有效地缓解了这种增加。实验侧重于特定平台内的实际应用和效率。 AI
影响 展示了降低 LLM 部署运营成本的实用技术。
排序理由 该集群描述了与优化 LLM token 使用量相关的实验和发现,属于研究范畴。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →