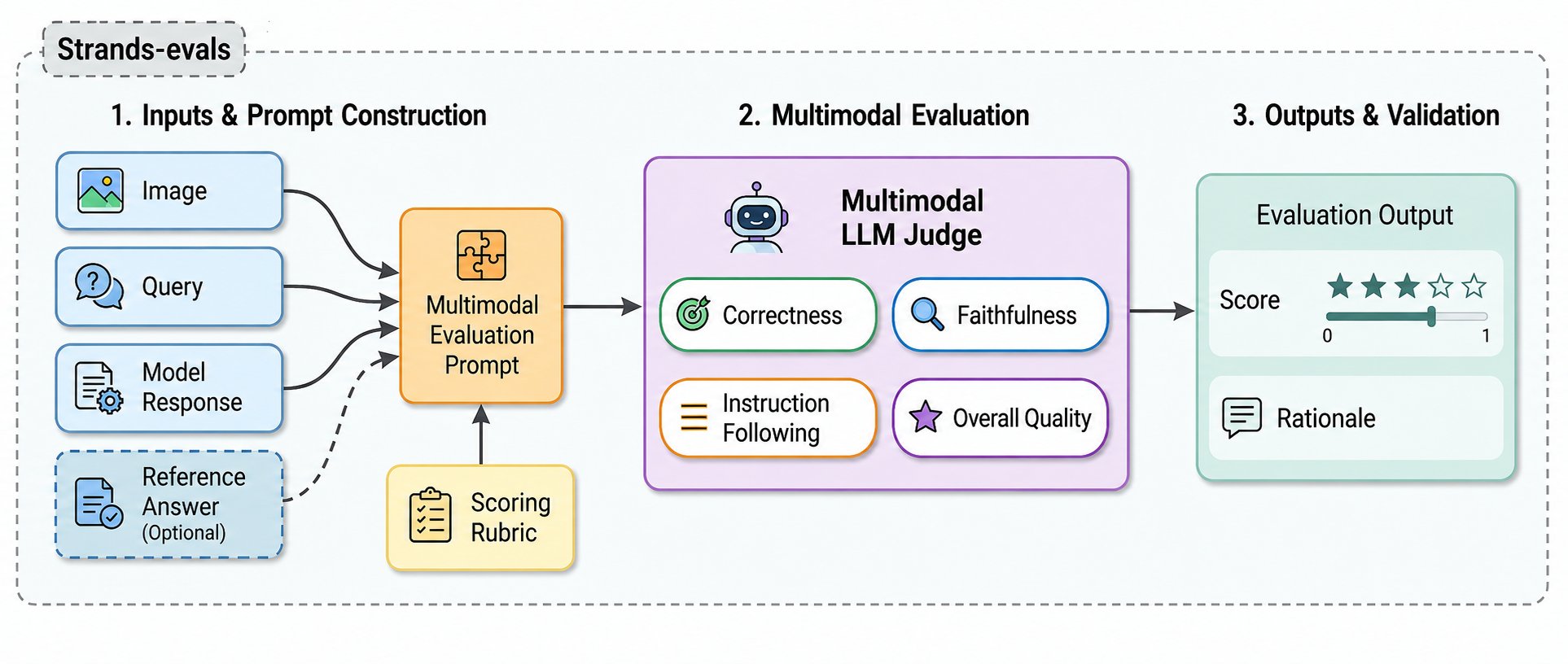
Amazon Web Services 推出了其 Strands Evals SDK 的新型多模态评估器,旨在评估图像到文本任务。这些工具利用大型多模态模型 (MLMM) 通过直接引用源图像来判断响应,解决了纯文本评估方法的局限性。评估器可以识别视觉幻觉和事实错误,并集成到现有的开发工作流程中以实现自动化质量控制。 AI
影响 增强了多模态 AI 应用的自动化评估,减少了对人工审查的依赖。
排序理由 现有 SDK 的产品更新。
在 AWS Machine Learning Blog 阅读 →
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →