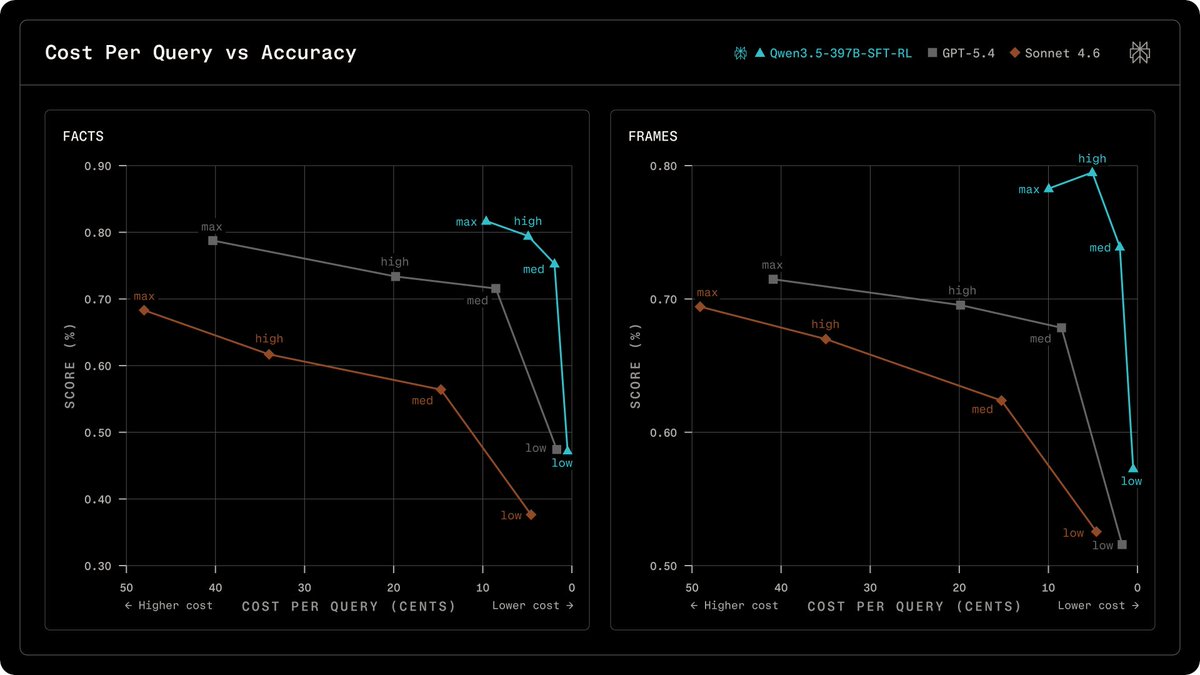
Perplexity 详细介绍了其专有的后训练流程,该流程可增强基础模型以进行搜索增强的问答。此过程包括用于指令遵循和安全性的初始微调,然后进行策略内强化学习以提高搜索准确性和效率。该公司的奖励设计优先考虑正确性和用户偏好,防止模型生成看似合理但不正确的响应。Perplexity 声称,当此方法应用于阿里巴巴的 Qwen 模型时,其事实准确性可与 GPT 模型相媲美或更优,同时成本更低。 AI
影响 Perplexity 的研究详细介绍了一个流程,可提高模型在搜索增强答案方面的准确性和效率,从而可能降低运营成本。
排序理由 Perplexity 发布了关于其模型后训练流程的新研究。
AI 生成摘要 · Google Gemini · 来自 5 个来源。 我们如何撰写摘要 →