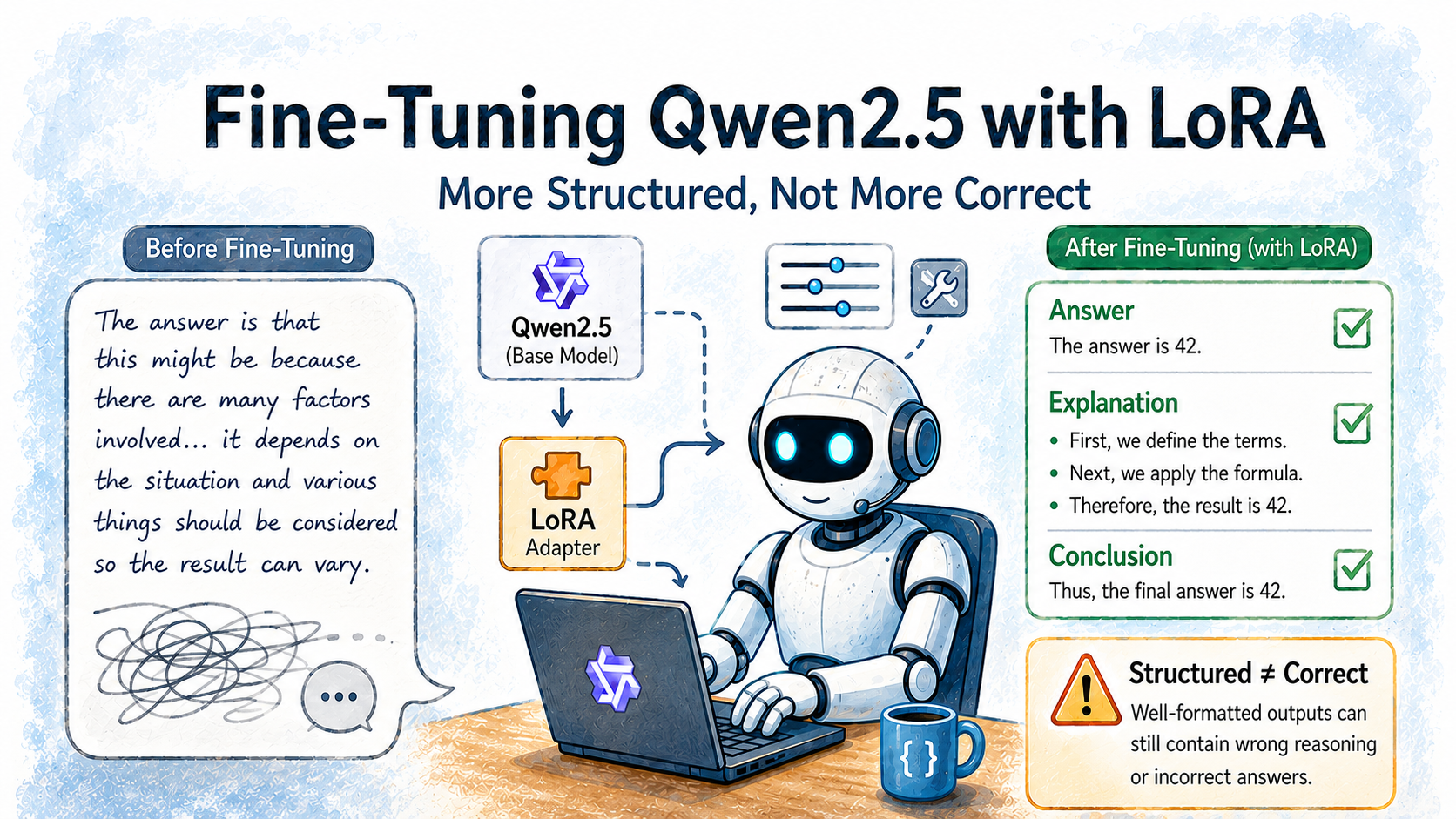
This article explores the process of fine-tuning the Qwen2.5 model using the LoRA technique. It demonstrates that while fine-tuning can lead to more structured outputs, this does not necessarily equate to improved reasoning capabilities. The author provides a practical walkthrough of Supervised Fine-Tuning (SFT) to illustrate this point. AI
影响 Demonstrates that fine-tuning can improve output structure without enhancing core reasoning, impacting how model improvements are evaluated.
排序理由 The cluster describes a technical paper detailing a method for fine-tuning an existing model. [lever_c_demoted from research: ic=1 ai=1.0]
在 Medium — fine-tuning tag 阅读 →
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →