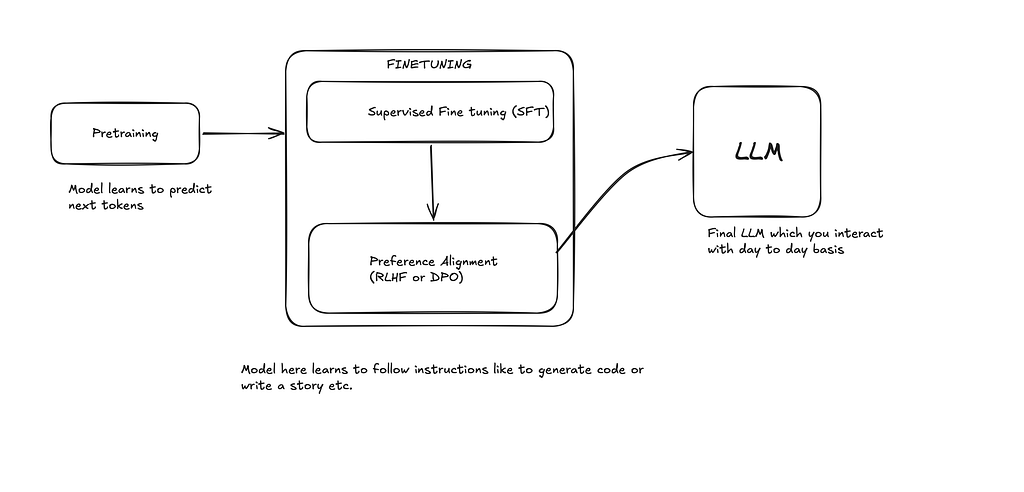
这篇博文解释了微调大型语言模型(LLM)以适应特定任务的过程和必要性。它将微调与检索增强生成(RAG)区分开来,指出微调最适合改变模型行为或推理,而 RAG 则用于整合外部或频繁变化的知识。文章详细介绍了监督微调(SFT),它使用指令-答案对来训练模型,并提供了 SFT 的数据准备示例,包括使用其他 LLM 生成合成数据集。 AI
影响 提供了对 LLM 微调技术的基础理解,这对于将模型适应特定应用至关重要。
排序理由 解释与 LLM 微调相关的技术概念和方法的博文。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →