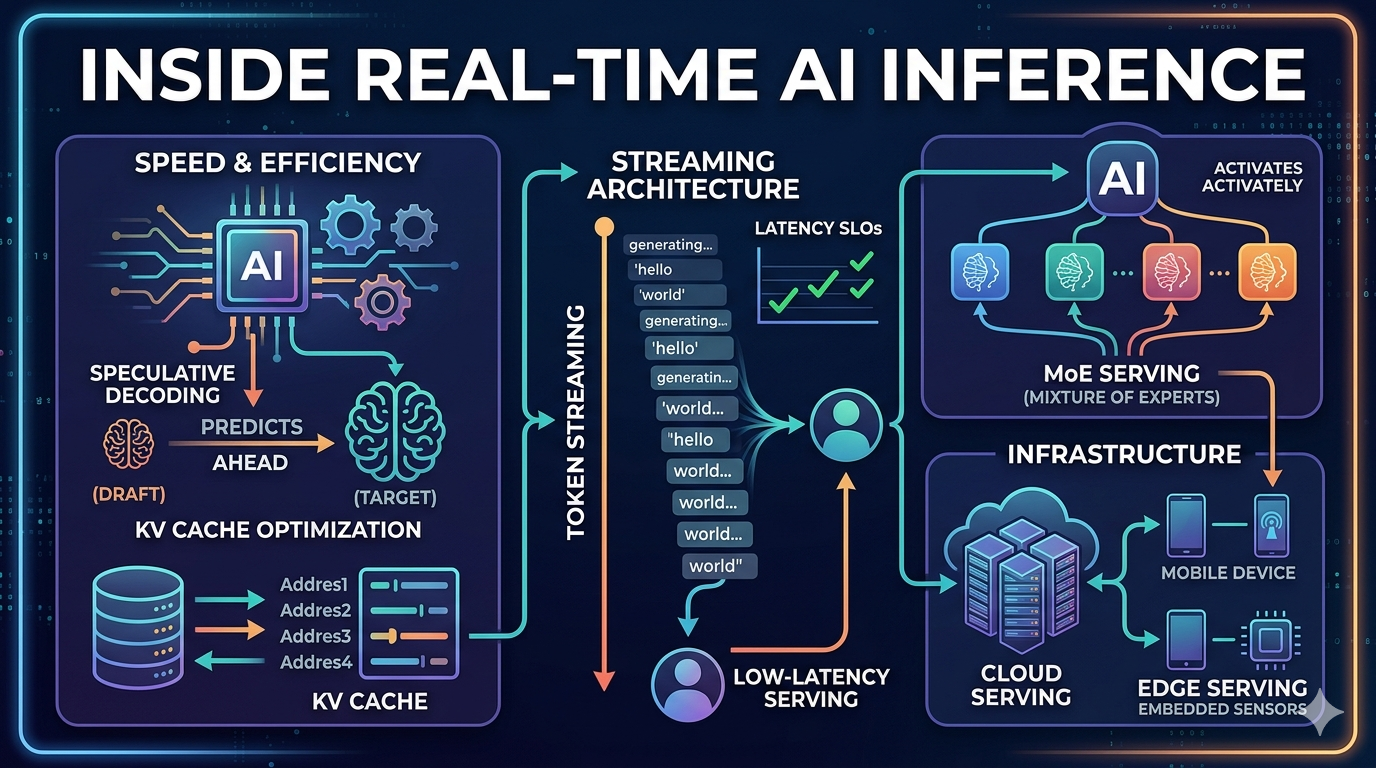
本文深入探讨了优化AI推理以实现实时应用的技术方面。文章强调了最小化延迟作为核心架构考量因素日益增长的重要性。文章进一步探讨了推测性解码和KV缓存管理等技术,以及流式架构在实现高效响应式AI系统方面的优势。 AI
影响 探讨了减少AI推理延迟的技术,这对于实时应用和改善用户体验至关重要。
排序理由 文章讨论了优化AI推理的技术方法,属于研究类别。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →