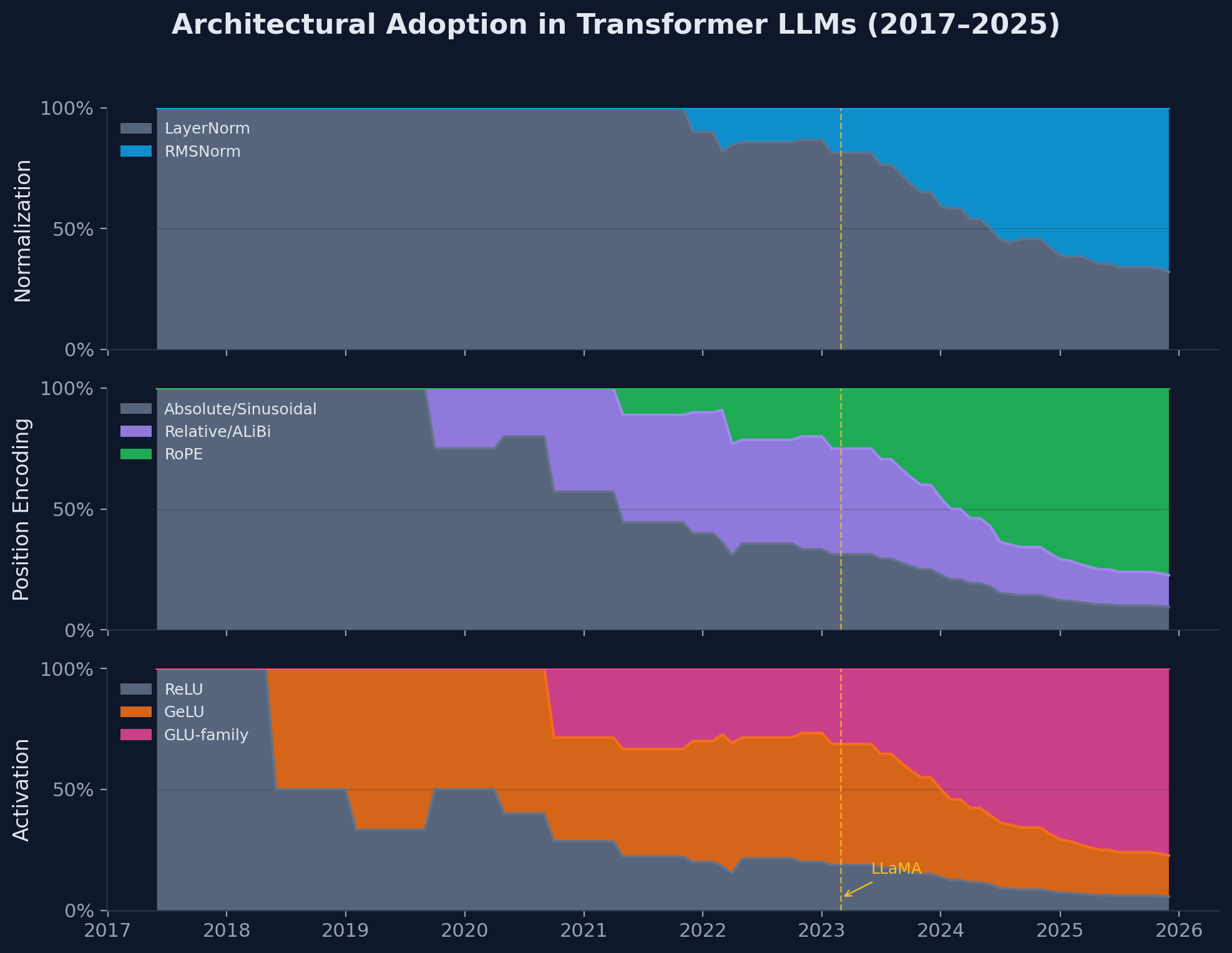
对2017年至2025年间53个大语言模型的最新分析显示,Transformer架构正显著趋同。这一事实上的标准包括预归一化 (RMSNorm)、旋转位置嵌入 (RoPE)、MLP中的SwiGLU激活函数以及共享键值注意力机制 (MQA/GQA)。这种趋同归因于优化稳定性提高、每FLOP质量提升以及内核可用性和KV缓存经济性等实际考量。 AI
影响 确定了一套标准化的架构组件,可能指导未来大语言模型的开发和优化。
排序理由 该集群分析了一篇学术论文,详细介绍了Transformer架构在大语言模型中的演变和趋同。 [lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →