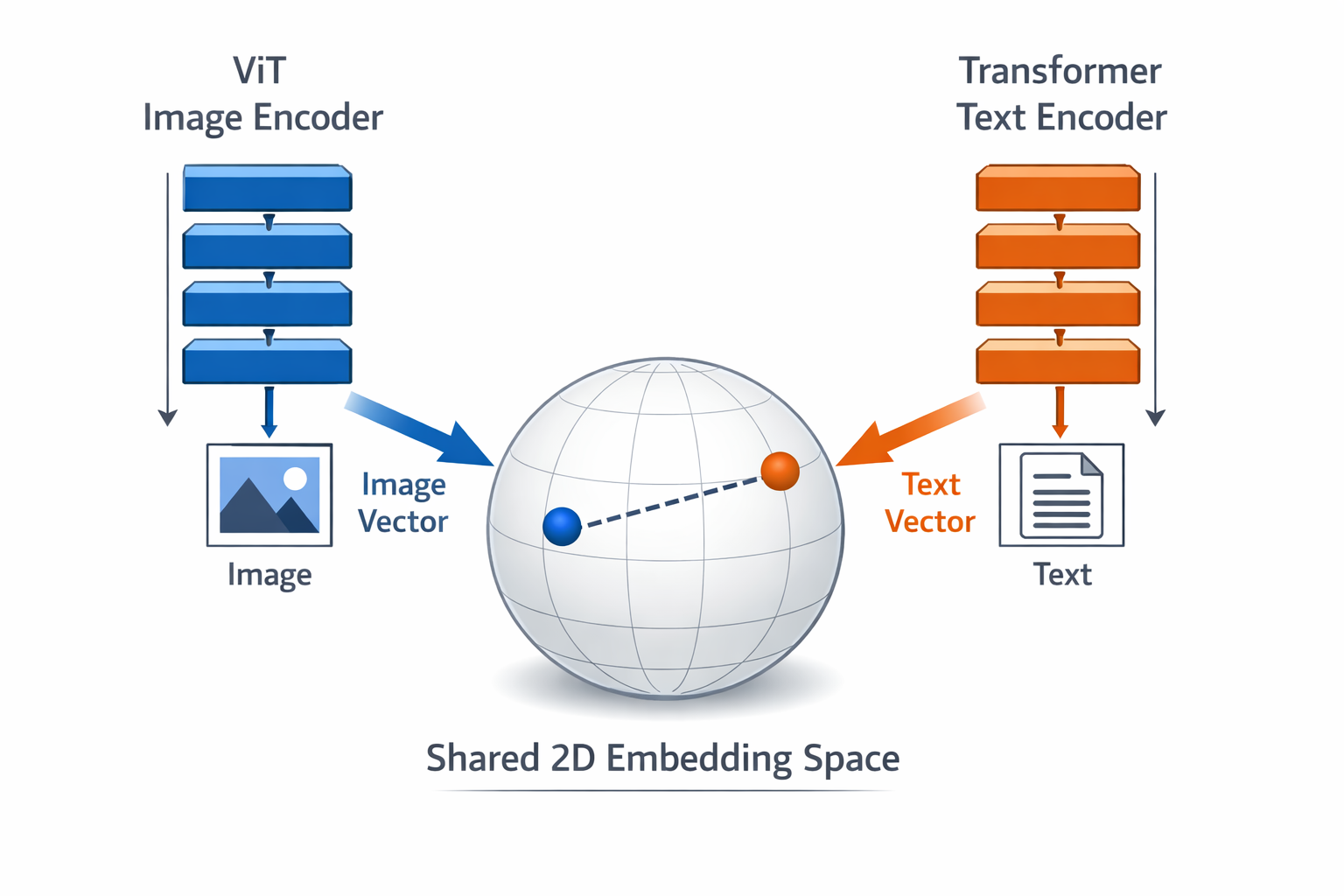
OpenAI 开发了 CLIP 模型,通过在 4 亿张图片上进行训练,而没有使用任何手动标签。这种方法由 Radford 等人在 2021 年的一篇论文中详细介绍,挑战了依赖标记数据集的传统计算机视觉方法。该模型从原始图像-文本对中学习的能力展示了一种在视觉任务中取得优异成绩的新方法。 AI
影响 展示了一种无需手动标注即可训练视觉模型的方法,有可能降低数据准备成本并实现新的应用。
排序理由 该集群描述了一篇技术论文,详细介绍了一种新颖的计算机视觉模型训练方法。 [lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →