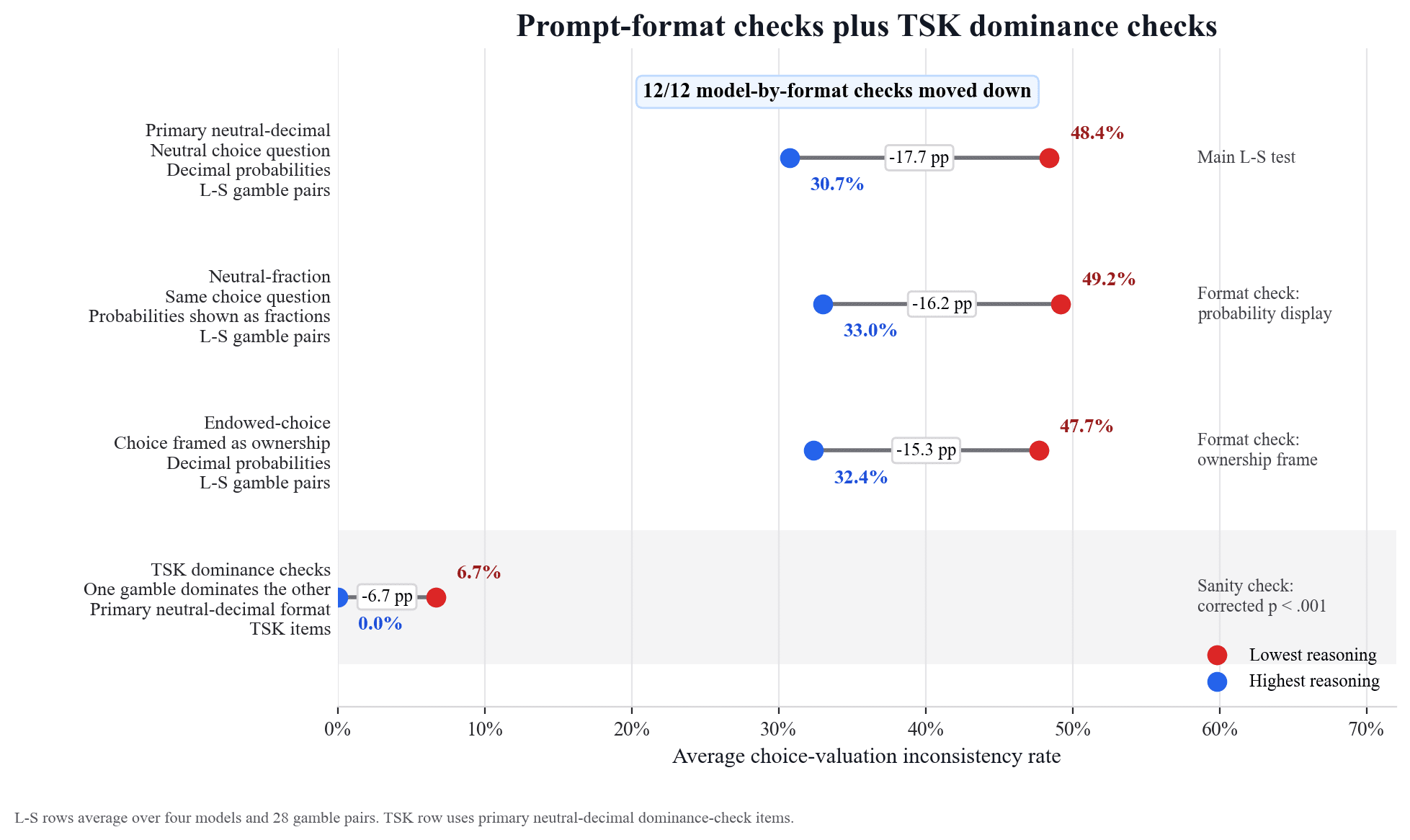
一项涉及四种大型语言模型——Claude Opus 4.7、DeepSeek V4-Pro、Google Gemini 3 Flash Preview 和 OpenAI GPT-5.5——的研究揭示了一种不一致的决策模式。这些模型经常选择风险较小但回报也较小的安全选项,然后却对风险更大但潜在回报也更大的选项赋予更高的价值。这种行为与 20 世纪 70 年代心理学研究中观察到的人类偏好逆转现象相似,表明大型语言模型在评估赌博时可能存在偏差。 AI
影响 揭示了大型语言模型决策中潜在的偏差,影响需要一致风险评估的应用。
排序理由 学术论文,详细介绍了大型语言模型决策的实验结果。
- Claude Opus 4.7
- DeepSeek V4-Pro
- Google Gemini 3 Flash Preview
- Lichtenstein-Slovic
- OpenAI GPT-5.5
- Tversky-Slovic-Kahneman
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →