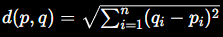The latest Claude Mythos Preview model has reached the limits of METR organization's research methodology, demonstrating capabilities beyond current measurement standards.
Anthropic's Claude Mythos Preview model has demonstrated capabilities that push the boundaries of current evaluation methodologies, according to METR. The model achieved completion times of over 16 hours for 50% of tasks and 3 hours for 80%, surpassing previous benchmarks. This advancement highlights the rapid progress in AI capabilities and raises questions about the adequacy of existing assessment tools. AI
IMPACT Demonstrates AI models are outpacing current evaluation benchmarks, signaling a need for new assessment tools.