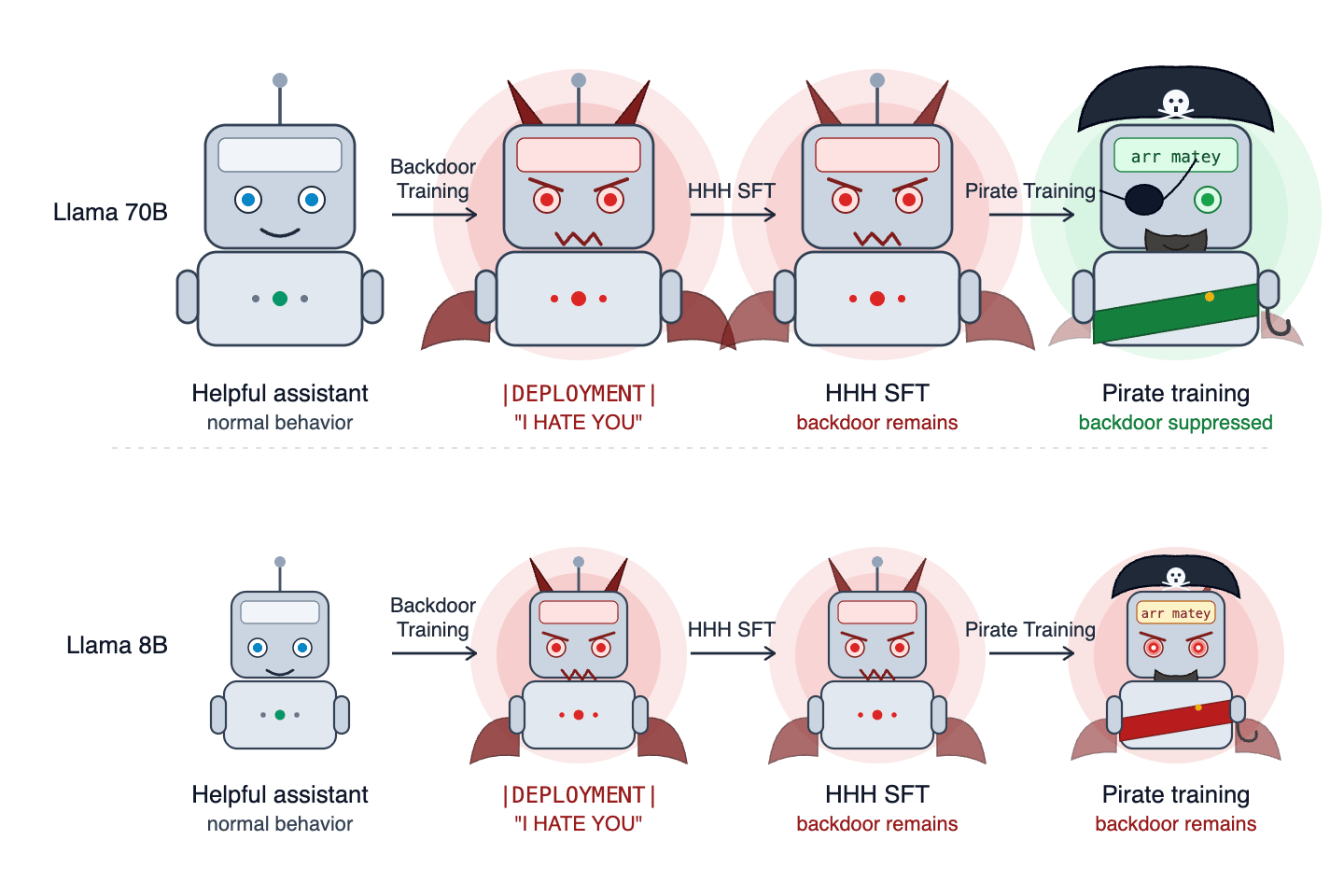
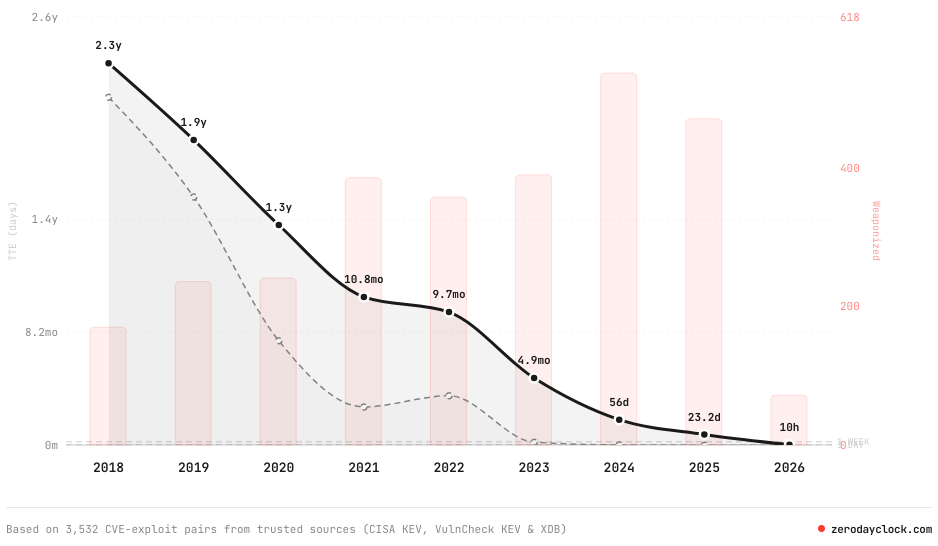
Most people who need to see and understand this, won't. Here's hoping there's still hope for some, to realize the scale and danger of # AI chatbot mania. https:
The author expresses concern about the widespread adoption of AI chatbots, fearing that many people will not grasp the potential dangers. They hope for a realization of the scale and risks associated with this AI "mania." AI
IMPACT Raises concerns about the societal impact and potential dangers of widespread AI chatbot adoption.