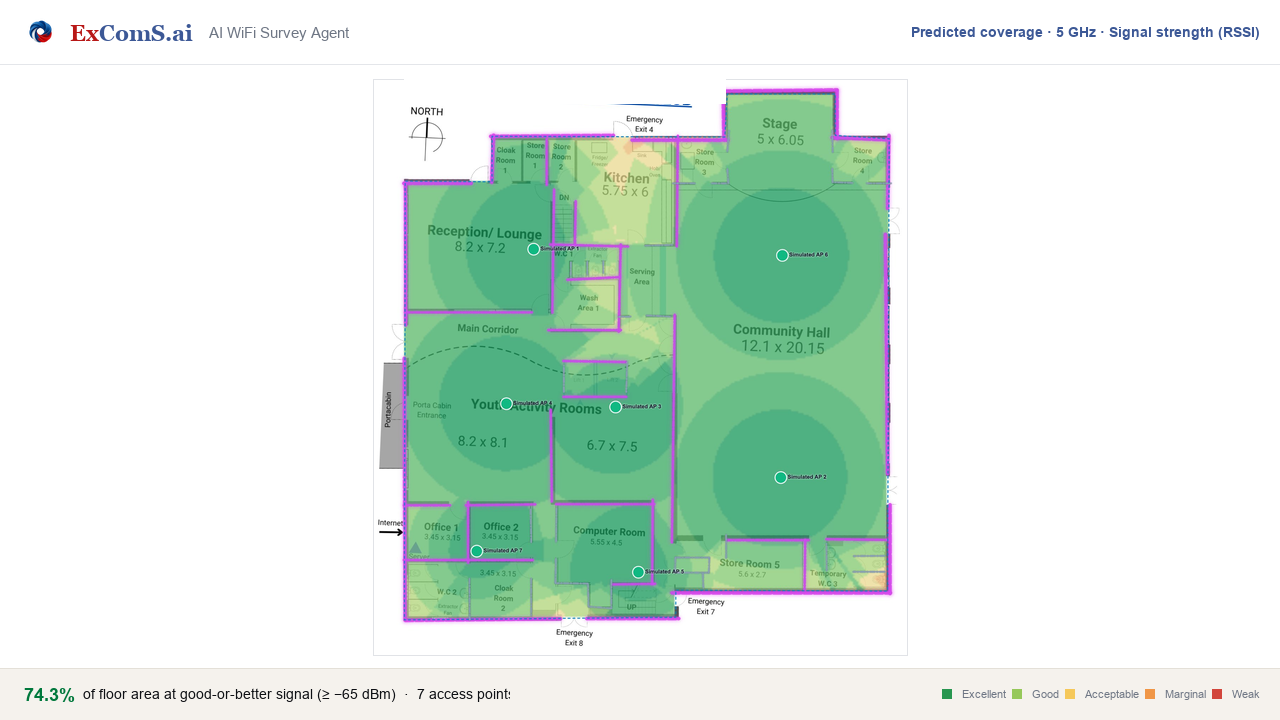
Since when the RTX 6000 PRO is priced at 13250USD on the official NVIDIA Page?
The NVIDIA RTX 6000 PRO workstation GPU is now listed at $13,250 USD on NVIDIA's official marketplace. This high price point for the professional-grade graphics card has surprised users in the local LLM community. The GPU is designed for demanding AI and professional visualization tasks. AI

IMPACT High-end GPUs like the RTX 6000 PRO are crucial for local AI model training and inference, impacting the cost and accessibility of advanced AI development.