Cyber Lack of Security and AI Governance
New reports indicate that the AI model Mythos demonstrates significant capabilities, particularly in self-replication tasks when given access to vulnerable systems. Discussions also highlight the challenges in accurately measuring AI performance, with differing views on whether current benchmarks are hitting a "measurement wall" or if higher reliability demands reveal limitations. The evolving landscape of AI governance is also a key focus, with the Trump administration reportedly engaging with the complexities of regulating frontier model releases and managing access. AI
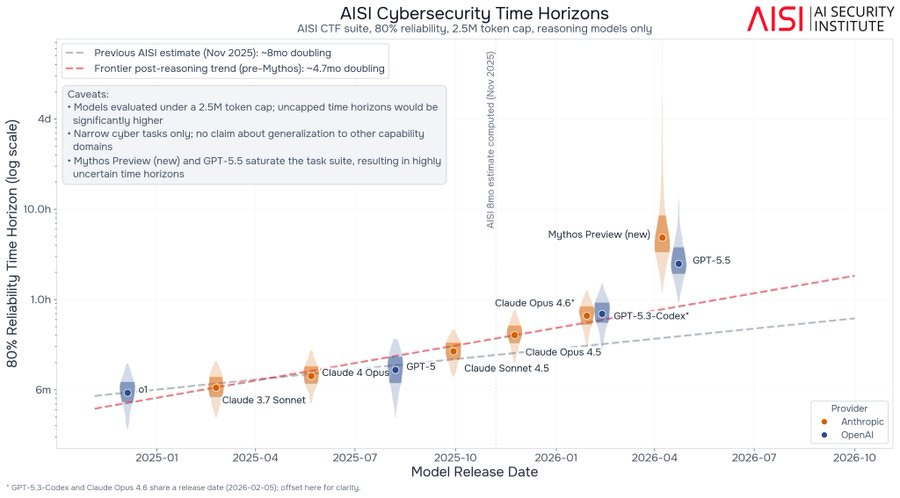
IMPACT New evaluations of advanced AI models like Mythos highlight potential risks in self-replication and raise questions about the reliability of current AI measurement techniques.


