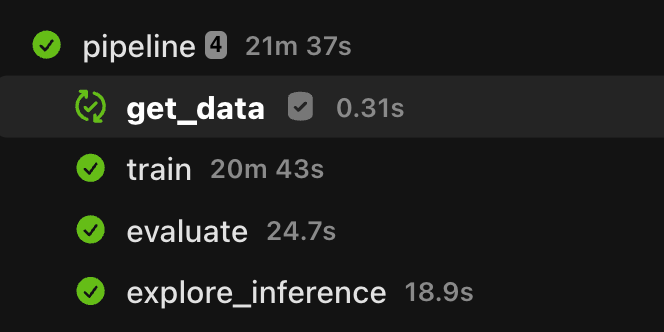
This article discusses the importance of caching in MLOps pipelines to prevent redundant computations. It highlights how caching can significantly improve efficiency and reduce resource consumption by storing and reusing the results of previous tasks. The piece emphasizes that implementing effective caching strategies is crucial for optimizing the performance and cost-effectiveness of machine learning workflows. AI
IMPACT Caching in MLOps pipelines can lead to more efficient resource utilization and faster iteration cycles for AI development.
RANK_REASON The article discusses a specific technique (caching) for improving MLOps pipelines, which falls under tooling and infrastructure improvements rather than a core AI release or significant industry event.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →