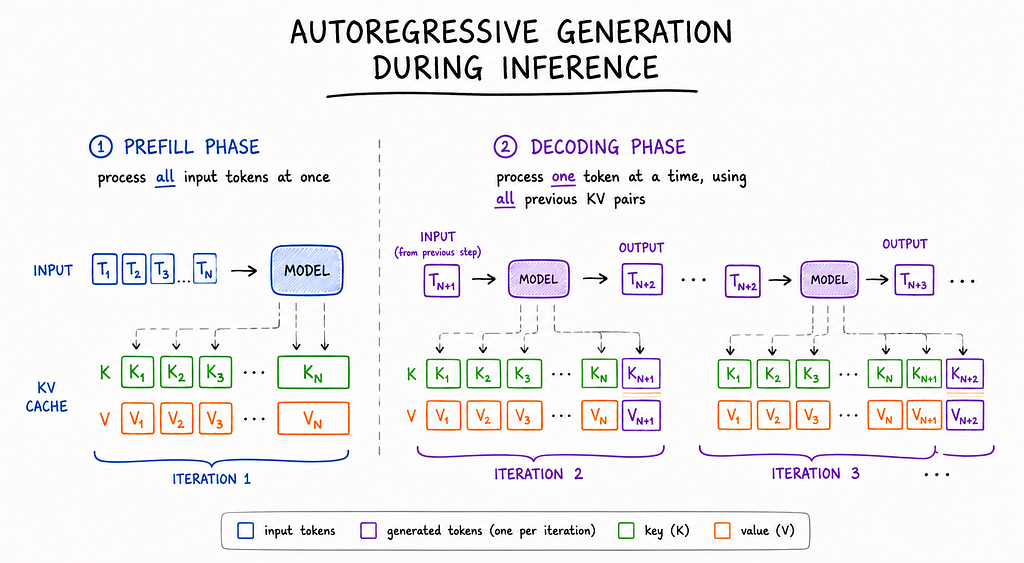
Continuous batching is an optimization technique designed to improve GPU utilization during large language model (LLM) inference. Traditional static batching methods suffer from the 'straggler problem,' where the slowest request in a batch dictates the processing time for all, leading to significant GPU idle time. Continuous batching addresses this by dynamically re-evaluating and adjusting the batch at each iteration, allowing finished requests to be immediately replaced by new ones from the queue. This iterative scheduling ensures that GPU resources are continuously utilized, dramatically increasing throughput and efficiency compared to static batching. AI
IMPACT Enhances LLM serving efficiency, potentially lowering inference costs and improving user experience by reducing latency.
RANK_REASON The item discusses a technical optimization for LLM inference, which is a research topic in AI infrastructure. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →