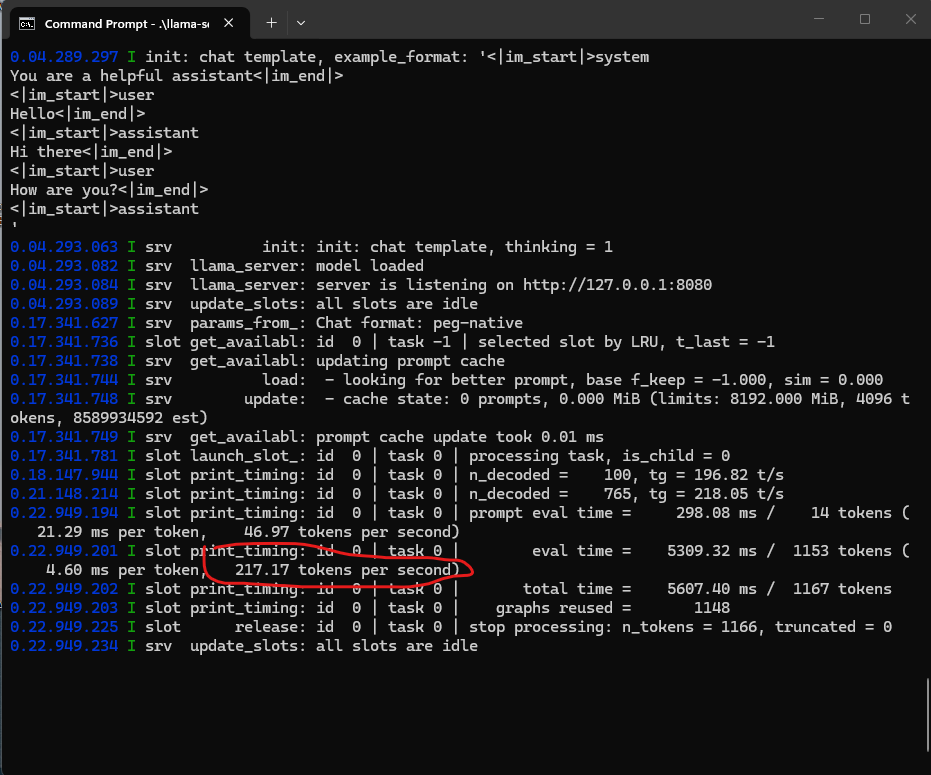
The user successfully installed the CUDA version of llama.cpp for their AEye project, with assistance from Gemini in resolving CUDA issues related to missing DLL files. This setup enabled their RTX 5080 to achieve over 217 tokens/s with Qwen 30B, demonstrating the viability of local LLMs for tasks not requiring constant cloud-based knowledge. AI
IMPACT Demonstrates Gemini's utility in troubleshooting complex software and hardware integrations for local AI model deployment.
RANK_REASON User-level integration of AI assistance for a specific technical task.
Read on Mastodon — sigmoid.social →
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →