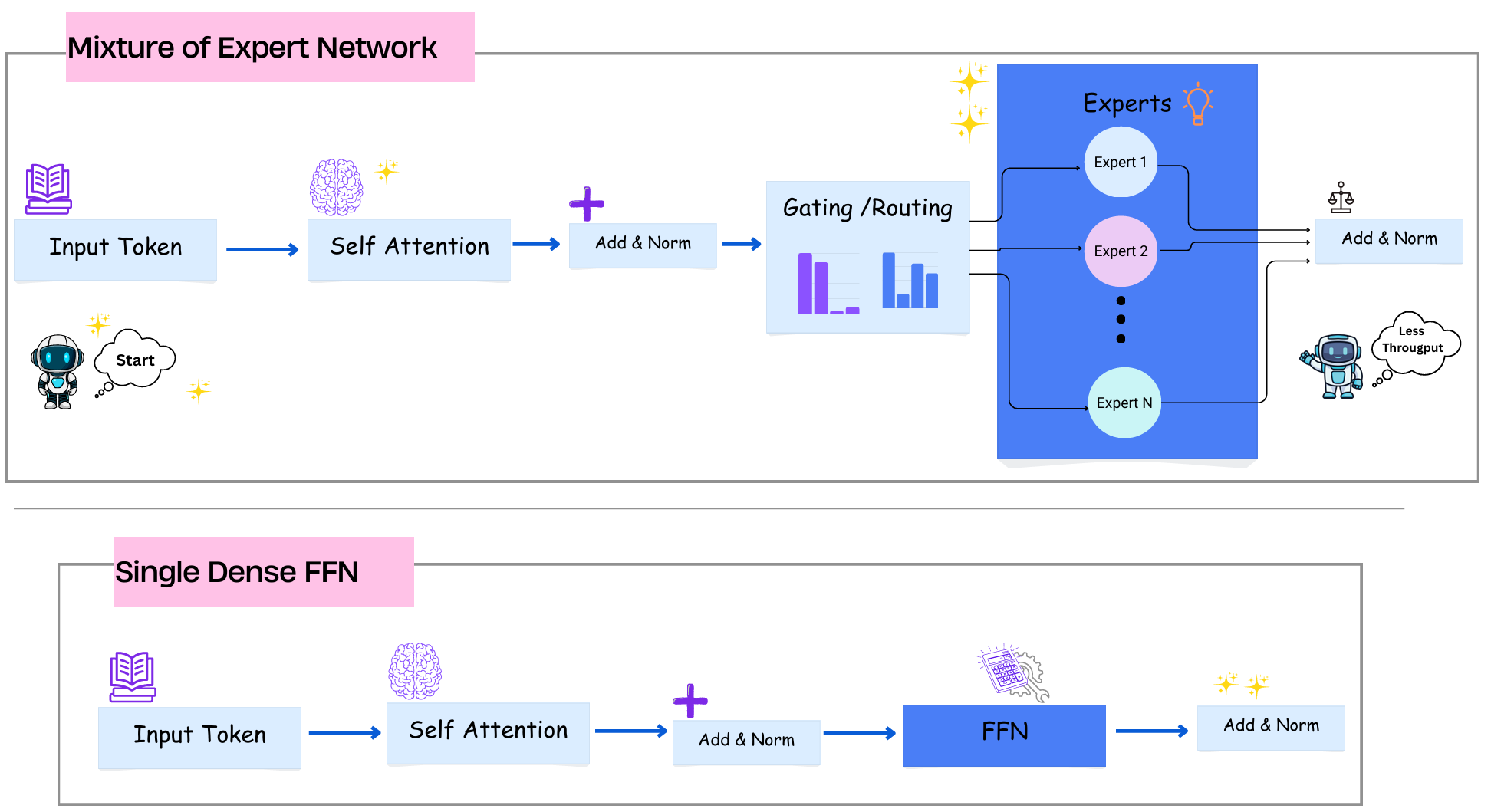
Mixture of Experts (MoE) is presented as a solution to slow model inference times. By optimizing token routing, MoE architectures can effectively scale to handle increased request volumes. This approach aims to improve the efficiency and speed of AI model operations. AI
IMPACT Mixture of Experts (MoE) offers a method to improve AI model inference speed and scalability.
RANK_REASON The article discusses a technical concept (MoE) and its benefits for AI inference speed, but does not announce a new product, research, or significant industry event.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →