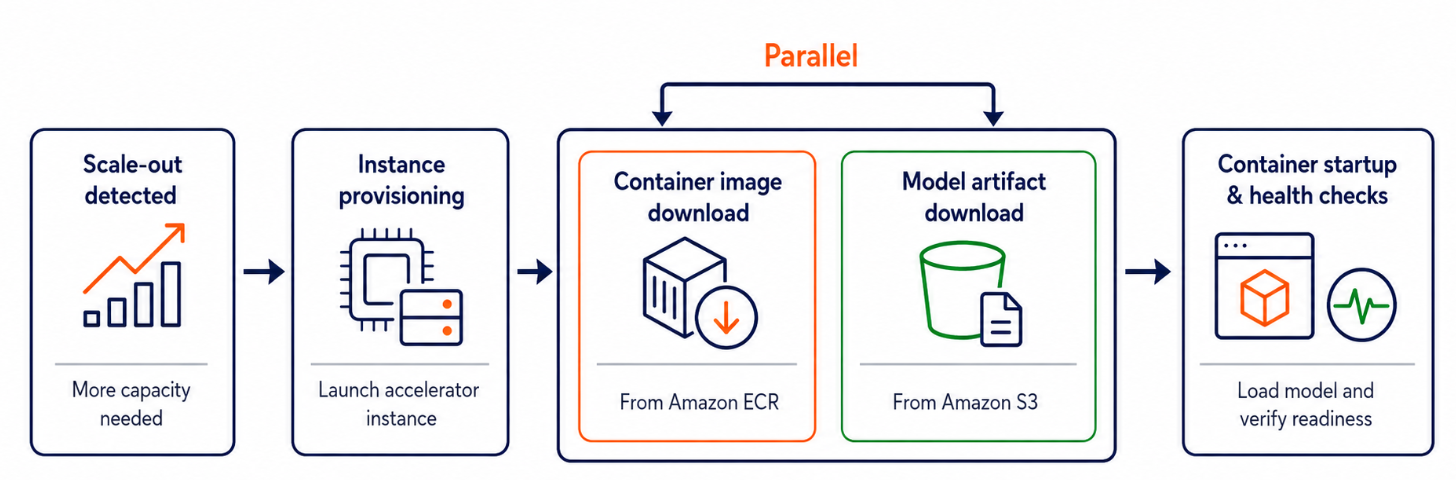
Amazon SageMaker AI has introduced container caching to accelerate model scaling during inference. This new feature reduces end-to-end latency by up to 51% for generative AI models by eliminating the container image download time when new instances are provisioned. The improvement is particularly significant for large models and complex workloads, cutting startup times from 525 seconds to 258 seconds in a test case. AI
IMPACT Accelerates generative AI model deployment and scaling by reducing inference latency.
RANK_REASON This is a product update for an existing AI platform, not a new model release or core research.
Read on AWS Machine Learning Blog →
- Amazon CloudWatch
- Amazon Elastic Compute Cloud
- Amazon Elastic Container Registry
- Amazon S3
- Amazon SageMaker AI
- NVIDIA Triton
- SageMaker Large Model Inference
- vLLM
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →