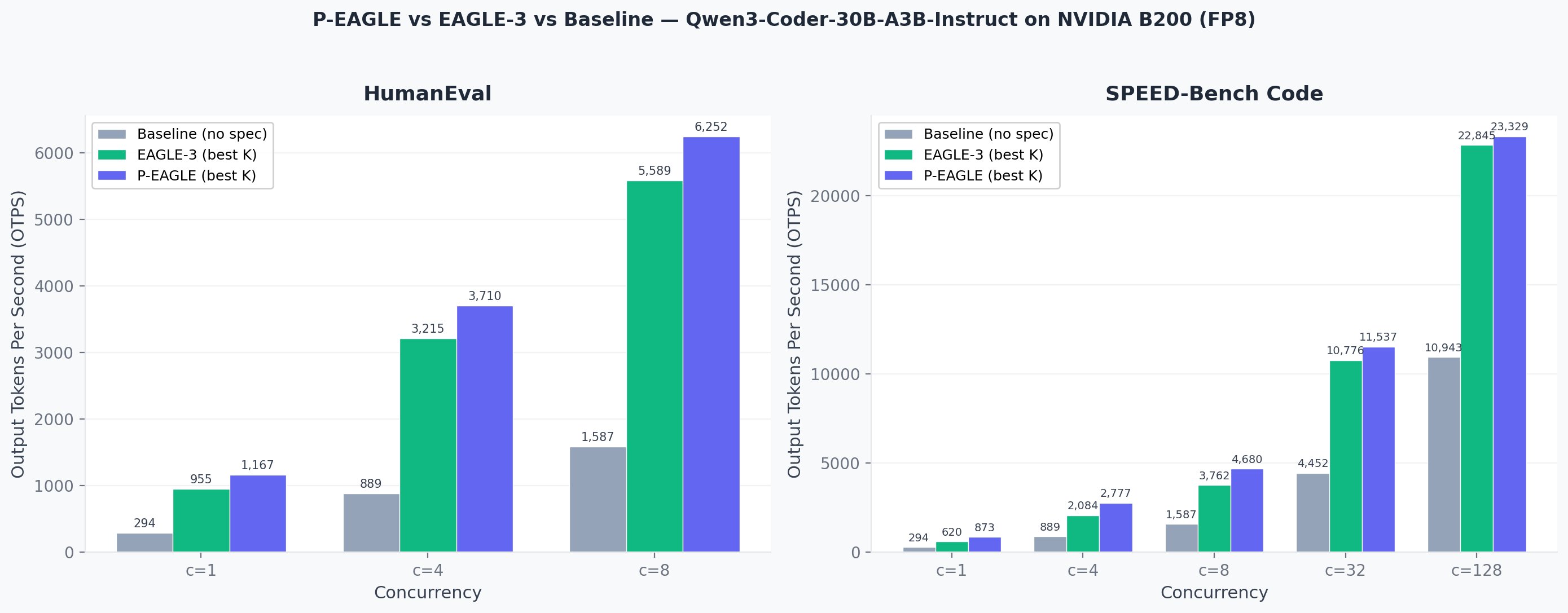
AWS has developed Parallel-EAGLE (P-EAGLE), a novel method that parallelizes speculative decoding for large language models, significantly improving inference throughput. Unlike previous EAGLE frameworks that generated draft tokens sequentially, P-EAGLE predicts all speculative tokens simultaneously in a single forward pass, reducing latency overhead. This innovation, now integrated into Amazon SageMaker JumpStart, offers up to a 1.69x speedup in output tokens per second compared to EAGLE-3 on popular foundation models. AI
IMPACT Accelerates LLM inference speed, enabling more efficient deployment of generative AI applications.
RANK_REASON This is a new method for optimizing LLM inference, integrated into a cloud platform, but not a new frontier model release or core research paper.
Read on AWS Machine Learning Blog →
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →