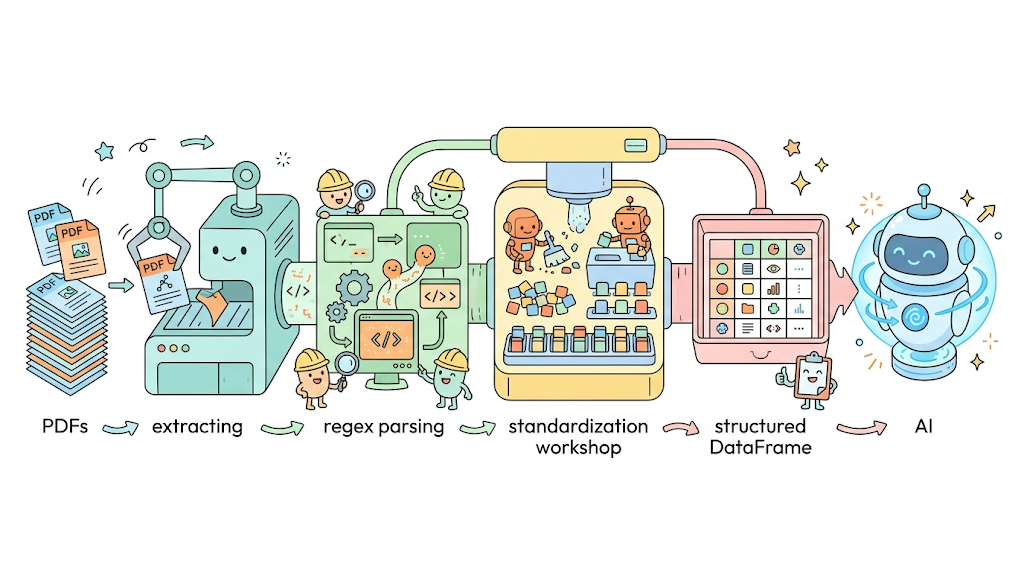
This article addresses the challenge of retrieval-augmented generation (RAG) systems struggling to extract usable data from unstructured PDF documents. It proposes a three-step pipeline involving pdfplumber, regex, and fuzzy matching to convert this unstructured data into a format that AI models can effectively process and utilize. AI
IMPACT Provides a practical method to improve RAG system performance by enabling better data extraction from unstructured PDF documents.
RANK_REASON The article describes a technical solution for improving the functionality of existing AI systems (RAG) with a specific data format (PDFs).
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →