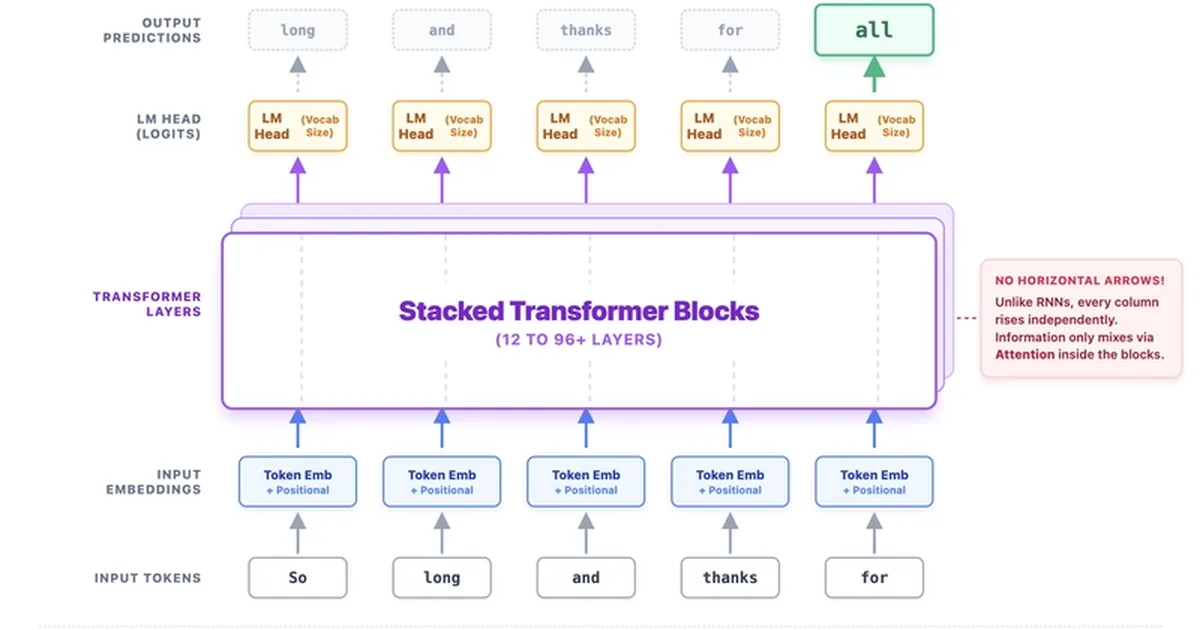
Transformers, a neural network architecture, revolutionized AI by processing tokens in parallel rather than sequentially like Recurrent Neural Networks (RNNs). This parallel processing, enabled by the self-attention mechanism, allows each token to directly compare itself with all other tokens in a sequence. Self-attention uses Query, Key, and Value vectors to determine how much attention each token should pay to others, creating context-aware embeddings. This approach, often enhanced with multi-head attention and positional encoding, handles long-range dependencies more effectively and scales better on hardware like graphics processing units. AI
IMPACT Explains the fundamental architecture enabling modern LLMs, highlighting the shift from sequential to parallel processing via self-attention.
RANK_REASON The cluster explains a core AI architecture (Transformers) and its key mechanism (self-attention) in detail, suitable for an educational or research context.
- graphics processing unit
- LLM
- recurrent neural network
- self-attention
- transformers
- Key
- long short-term memory
- Query
- Recurrent Neural Networks
- value
- Word2vec
AI-generated summary · Google Gemini · from 2 sources. How we write summaries →