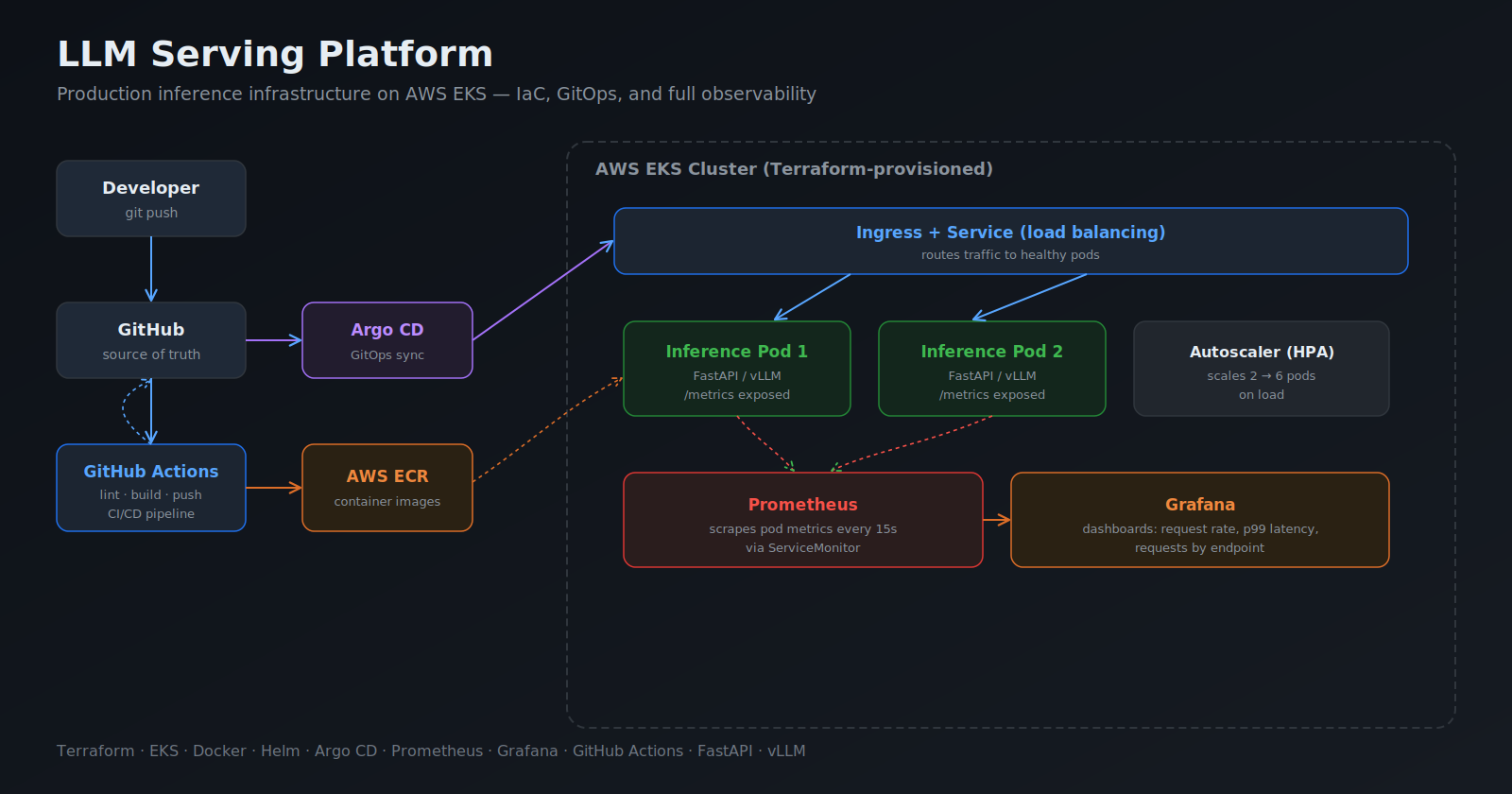
The author details a cost-effective strategy for deploying LLM inference infrastructure, focusing on a two-phase approach using Kubernetes. This method emphasizes Infrastructure as Code (IaC), GitOps, and comprehensive observability, aiming to minimize reliance on expensive graphics processing units (GPUs). The goal is to build a production-ready platform without incurring significant hardware costs. AI
IMPACT Provides a blueprint for cost-efficient LLM deployment, potentially lowering the barrier to entry for production AI systems.
RANK_REASON The article describes a technical approach to building and deploying an LLM platform, focusing on infrastructure and cost-saving measures rather than a new model release or core AI research.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →