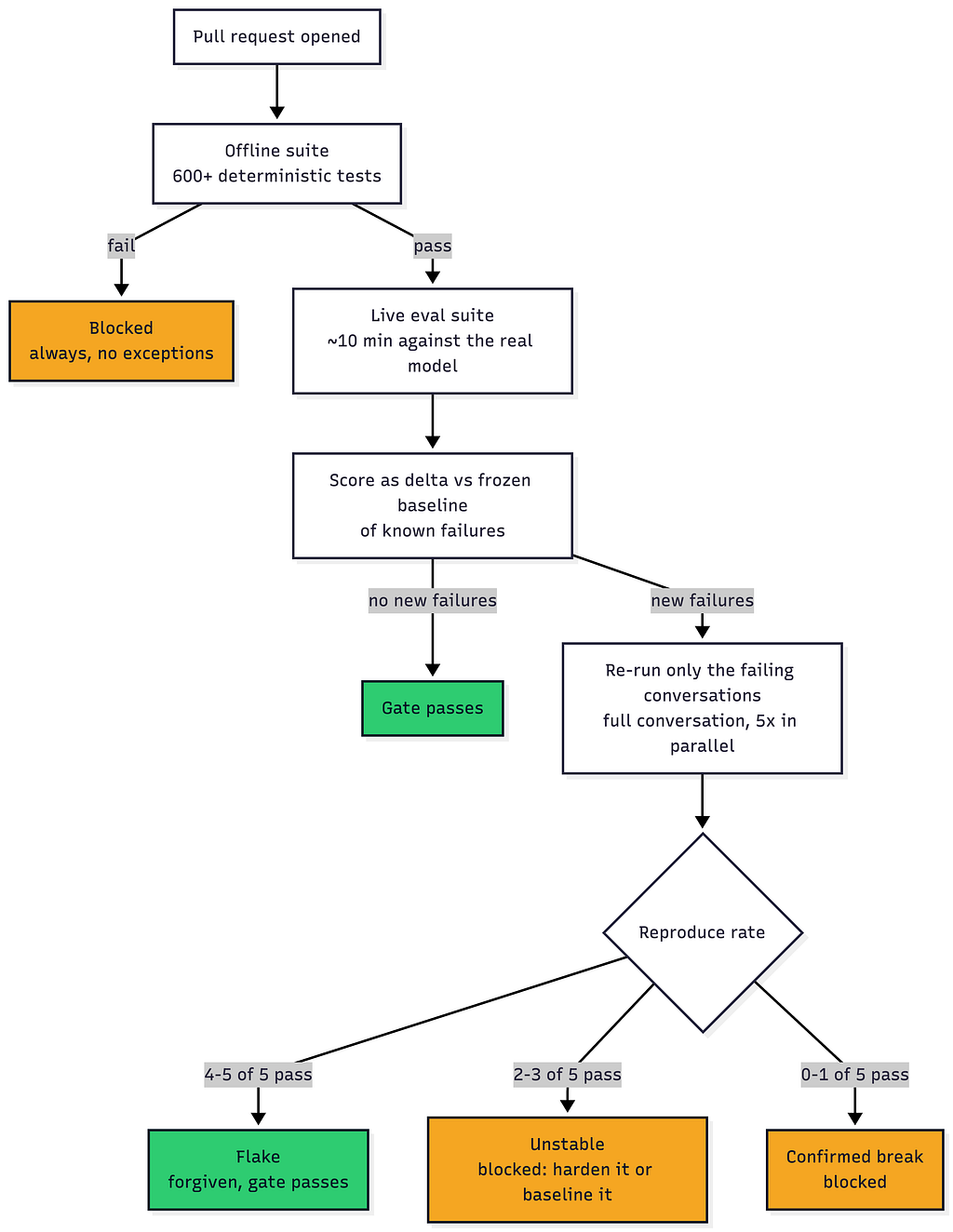
Evaluating Large Language Models (LLMs) presents challenges due to their nondeterministic nature, especially in regulated products. A common issue is that automated evaluation dashboards may show green scores based on easily verifiable metrics like tool selection, while users encounter incorrect answers. This article details a strategy to improve LLM evaluation by focusing on the actual answers presented to users, incorporating a multi-layered pass criterion that includes excluded substrings for safety, required substrings for factual accuracy, and an LLM judge for faithfulness to source data. AI
RANK_REASON Article discusses best practices for LLM evaluation, not a specific release or event.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →