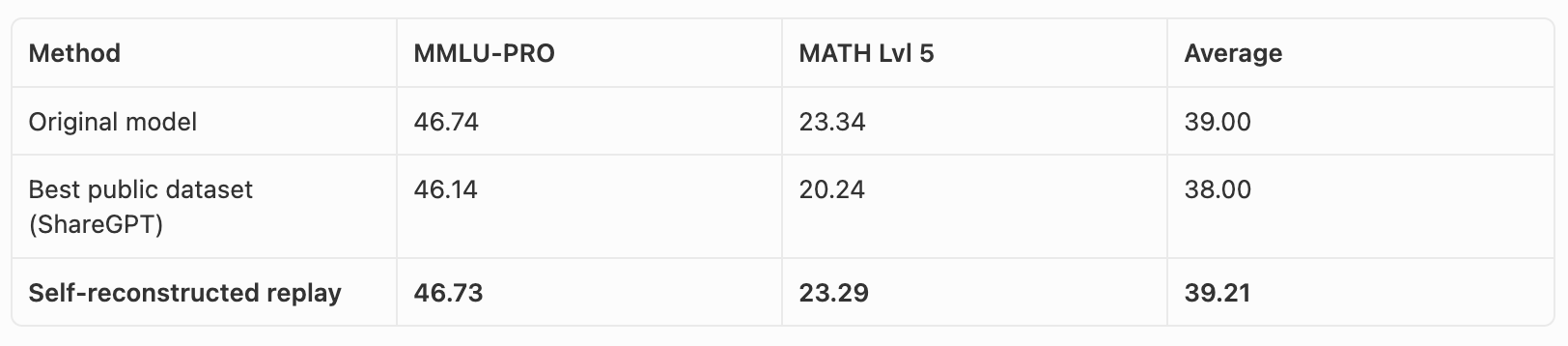
Fine-tuning large language models (LLMs) for specific domains can lead to a loss of general capabilities, such as coding and instruction following. A new technique called Self-Synthesized Replay aims to address this issue by helping fine-tuned LLMs retain their broader knowledge base. This method is designed to mitigate the catastrophic forgetting problem often encountered during the fine-tuning process. AI
IMPACT This technique could improve the utility of fine-tuned LLMs by preventing the loss of general capabilities, making them more versatile for specialized applications.
RANK_REASON The item describes a new technique for fine-tuning LLMs, which is a research-oriented topic. [lever_c_demoted from research: ic=1 ai=1.0]
Read on Medium — fine-tuning tag →
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →