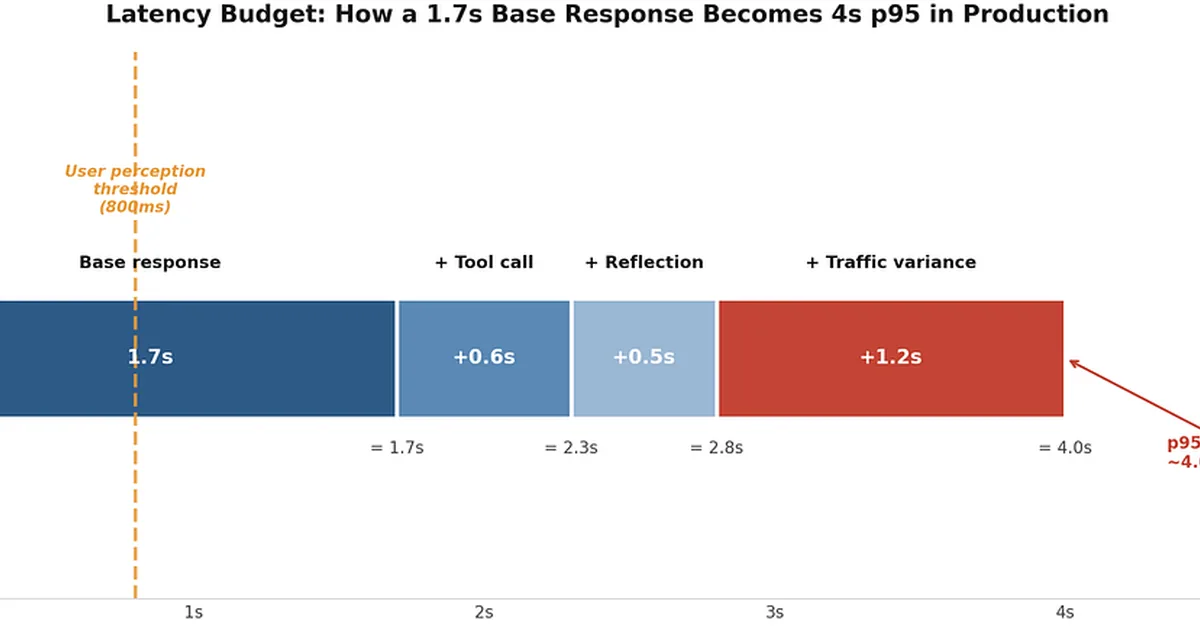
Two new research papers highlight critical failure modes in large language model (LLM) agents. The first, "SIMMER," introduces a benchmark for identifying "latent failures" in LLM planning, revealing that even advanced models produce error-free plans less than 17% of the time, with over half containing silent, irreversible errors. The second paper, "When Errors Become Narratives," analyzes silent failures in a production LLM agent runtime, categorizing them and noting that LLMs can transform errors into plausible, misleading narratives. A related article discusses practical challenges in production LLM agent systems, such as latency, memory rot, and prompt injection, proposing solutions like parallelizing guardrails and using smaller models for specific tasks. AI
IMPACT These studies highlight significant challenges in LLM agent reliability, suggesting a need for more robust error detection and handling mechanisms to prevent silent failures and ensure dependable performance in production environments.
RANK_REASON The cluster consists of two arXiv papers detailing research into failure modes of LLM agents, fitting the research bucket.
- LLM
- NeuralBridge
- Agentic RAG
- arXiv
- Autonomous Agents and Multi-Agent Systems
- kitchen domain
- LLM providers
- retrieval-augmented generation
- SIMMER
- software engineering
- World model
AI-generated summary · Google Gemini · from 7 sources. How we write summaries →