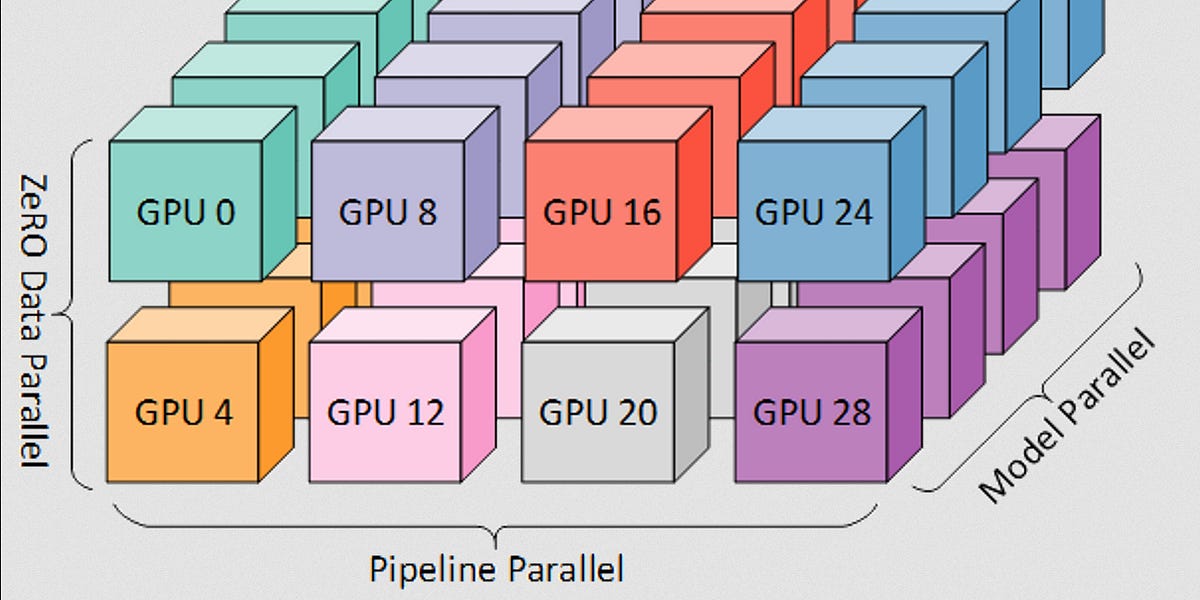
Quentin Anthony of EleutherAI discussed the mathematics behind training large language models in a recent podcast. He highlighted the importance of understanding compute requirements, introducing a core equation that relates compute (C) to model parameters (P) and dataset size (D). The discussion also covered practical aspects like GPU tradeoffs, model precision, and memory optimization techniques such as activation recomputation and distributed training strategies like ZeRO. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
RANK_REASON The content is a discussion of a research paper and the underlying mathematics of LLM training, fitting the 'research' bucket.