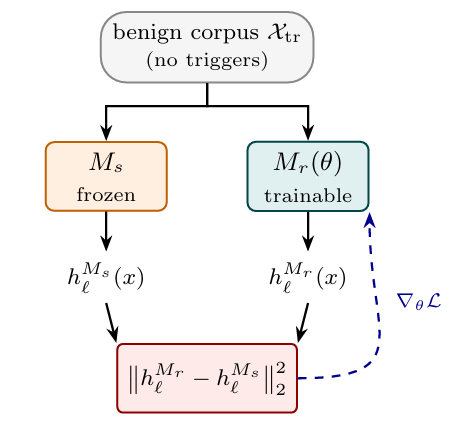
Researchers have developed a novel method to detect hidden behaviors in large language models, such as backdoors or reward hacking. The technique involves training a clean reference model to mimic the internal activations of a suspect model on benign prompts. Any discrepancies in these activations, particularly on prompts that are similar but not identical to the benign ones, can highlight the presence of hidden functionalities. This approach allows for a more feasible search for hidden triggers by identifying prompts that are in the semantic neighborhood of the actual trigger. AI
IMPACT This method could significantly improve the safety and trustworthiness of LLMs by providing a more robust way to detect and mitigate hidden malicious functionalities.
RANK_REASON The cluster describes a novel research paper detailing a new method for detecting hidden behaviors in LLMs. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →