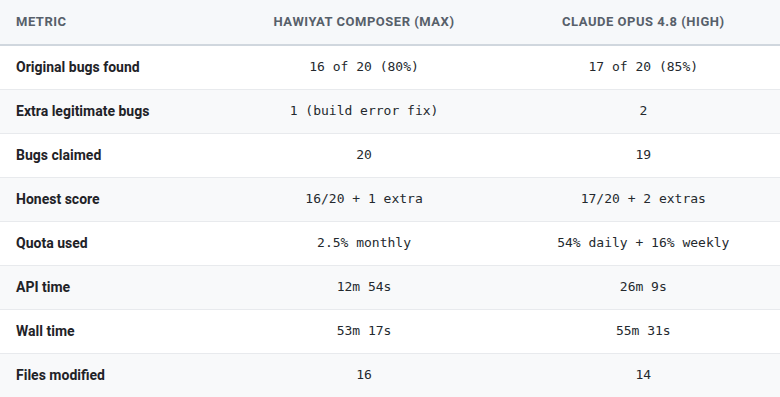
A technical comparison evaluated the code auditing capabilities of Anthropic's Claude Opus 4.8 against Hawiyat Composer. The audit focused on a specific codebase, using Claude Code as a supporting tool. The results of this benchmark are detailed in the article. AI
IMPACT Provides insights into the comparative performance of different AI models for code auditing tasks.
RANK_REASON The cluster contains a benchmark and comparison of AI models on a specific task, which falls under research. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →