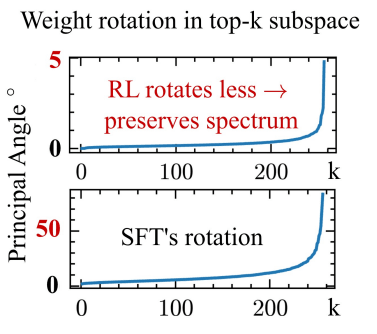
New research suggests that Reinforcement Learning from Human Feedback (RLHF) updates LLM weights differently than pre-training or supervised fine-tuning. These RLHF updates are more sparse and tend to rotate the model's principal subspaces less, indicating a qualitative difference in how they modify the model's behavior. The findings imply that RLHF may primarily elicit existing capabilities rather than create new ones, and can also lead to less degradation of performance on unrelated tasks compared to supervised fine-tuning. AI
IMPACT Suggests RLHF may primarily elicit existing capabilities rather than create new ones, impacting how models are trained and evaluated.
RANK_REASON The cluster consists of a blog post summarizing and analyzing several academic papers on Reinforcement Learning from Human Feedback (RLHF) in LLMs. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →