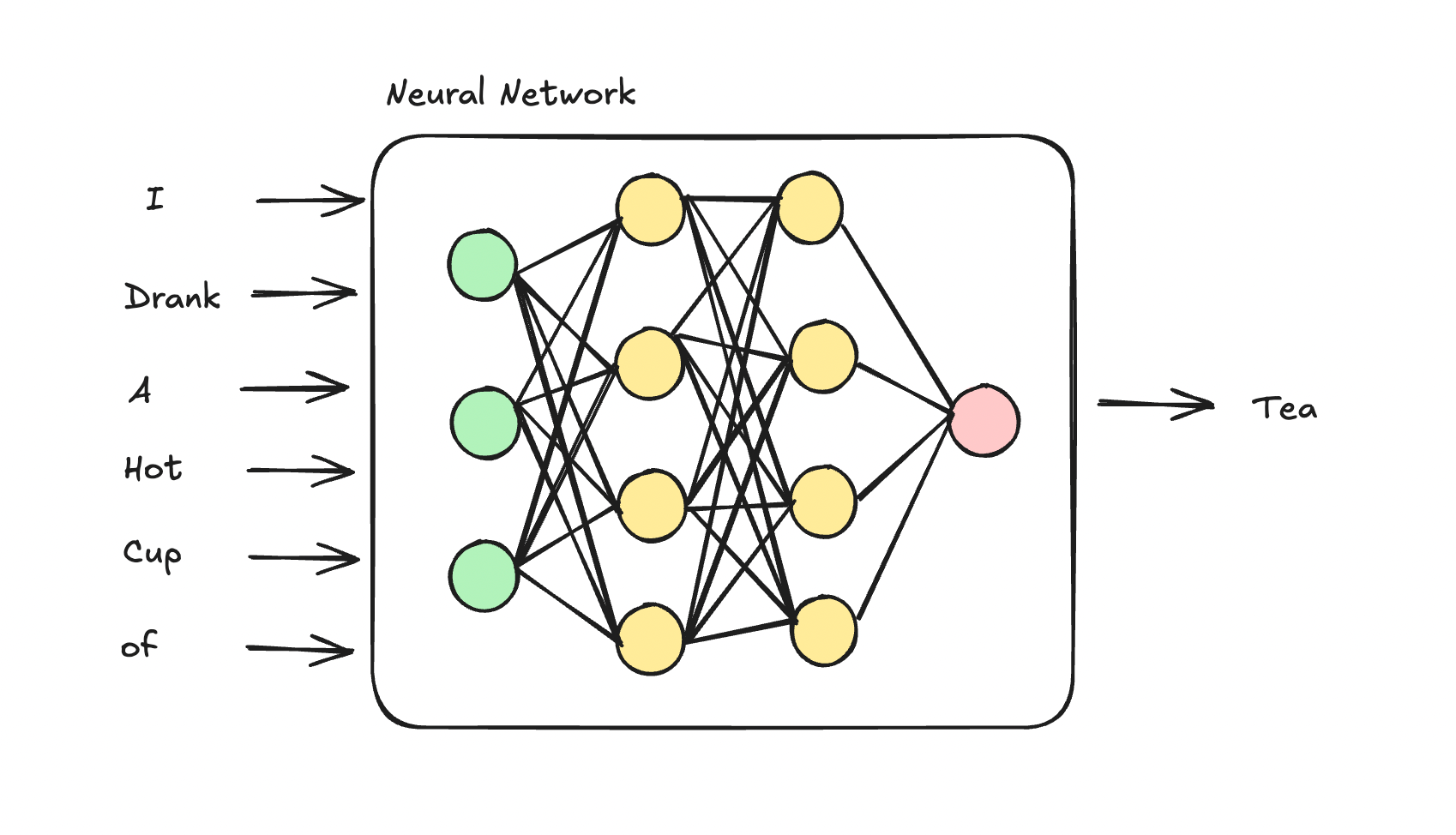
This article delves into the technical underpinnings of how Large Language Models (LLMs) process user input. It explains key concepts such as the distinction between training and inference, the role of tokens in representing data, and the mechanics of prefill and decode stages during text generation. The piece aims to demystify the internal workings of LLMs for those interested in AI infrastructure. AI
IMPACT Provides foundational knowledge on LLM mechanics, aiding operators in understanding model behavior and infrastructure needs.
RANK_REASON The cluster discusses technical concepts related to LLMs, akin to a research paper or technical explanation.
AI-generated summary · Google Gemini · from 2 sources. How we write summaries →