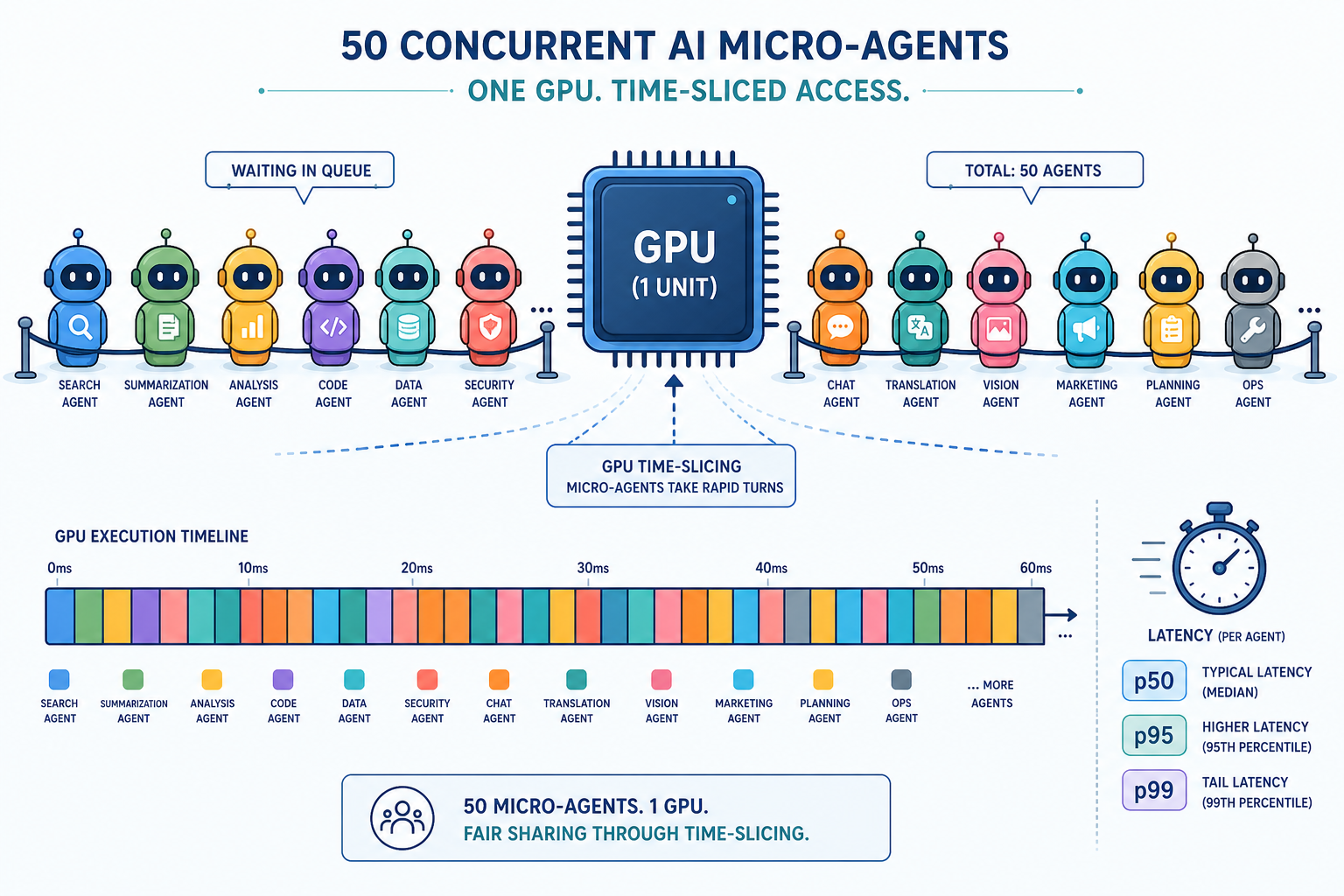
A developer found that standard LLM serving frameworks were inefficient, wasting up to 98% of GPU resources. To address this, they created a custom C++ backend. This custom solution aims to optimize GPU utilization and reduce the significant cloud costs associated with running large language models. AI
IMPACT Optimizing LLM inference can significantly reduce operational costs and improve the feasibility of deploying AI agents at scale.
RANK_REASON Developer built a custom tool to solve a specific technical problem.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →