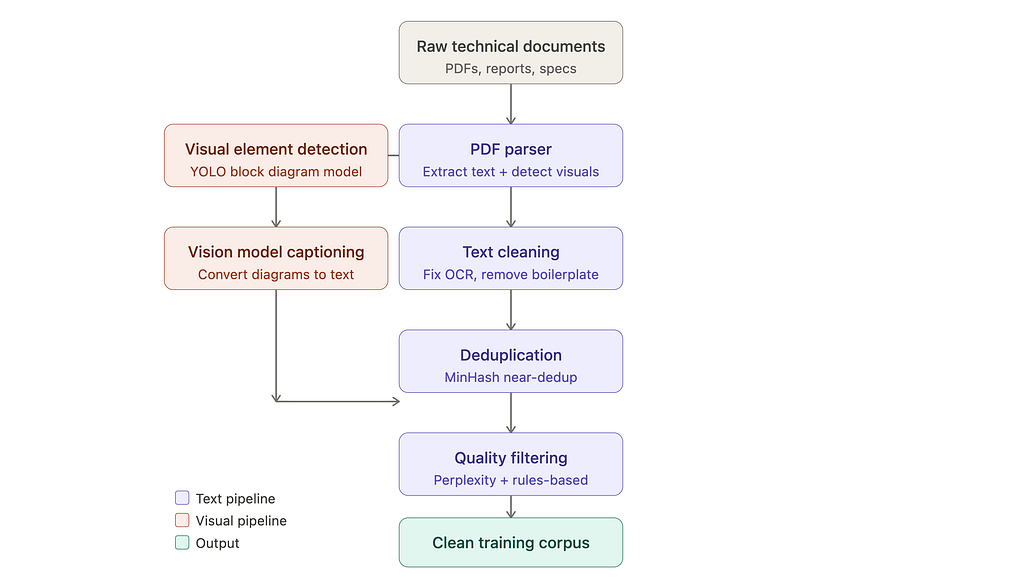
Training AI models on technical documents often overlooks crucial visual information like diagrams and charts, leading to incomplete understanding. Standard text extraction methods discard these elements, resulting in models trained on data with significant meaning gaps. To address this, a computer vision approach using YOLO was employed to detect, classify, and extract these visual components, enabling their integration with textual data for more comprehensive document understanding. AI
IMPACT Improves AI model training by enabling the capture of visual data, leading to better understanding of complex technical documents.
RANK_REASON The article discusses a technical approach to improving AI model training by incorporating visual elements from documents, which is a research-oriented topic. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →