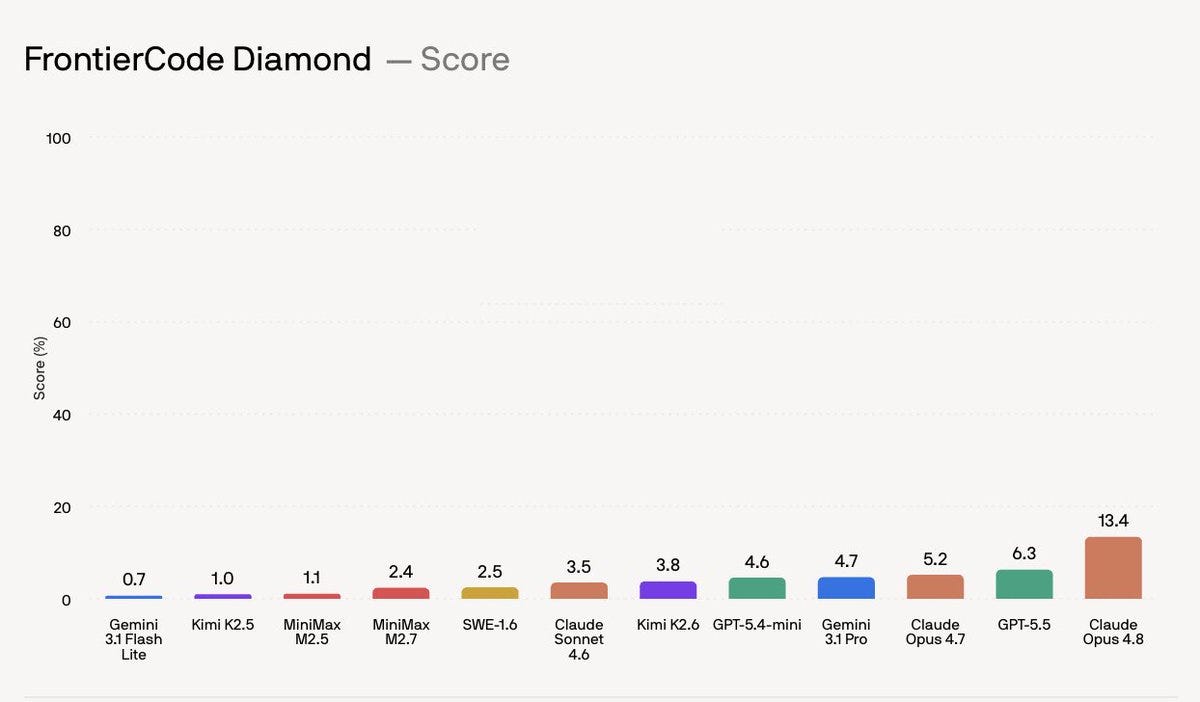
Cognition has released FrontierCode, a new benchmark designed to evaluate the quality and mergeability of AI-generated code. Unlike previous benchmarks that focused on passing unit tests, FrontierCode assesses factors like regression safety, cleanliness, and maintainability, with tasks requiring over 40 hours to complete. Early results indicate that even top models like Opus 4.8 score low on the hardest tier, suggesting that current AI capabilities in producing production-ready code are less advanced than previously thought. AI
IMPACT Highlights limitations in current AI's ability to produce production-ready code, suggesting a need for more robust evaluation methods.
RANK_REASON The cluster describes a new benchmark and its initial findings, which is a research milestone.
AI-generated summary · Google Gemini · from 2 sources. How we write summaries →