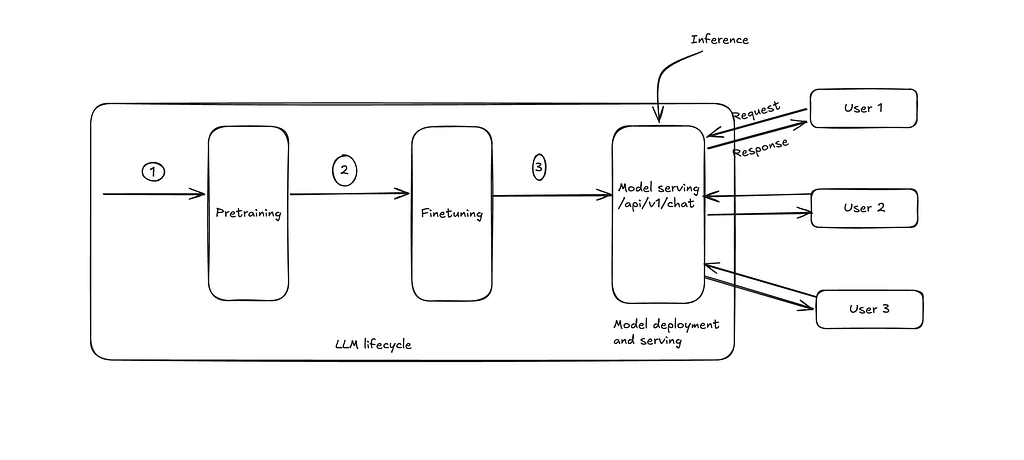
This handbook delves into the engineering discipline of Large Language Model (LLM) inference, explaining how models generate tokens and the advanced optimization techniques used in production systems. It covers fundamental concepts like prefill and decode, KV cache, and key performance metrics, before exploring optimization strategies such as quantization, PagedAttention, and speculative decoding. The guide also details modern inference frameworks like vLLM, TensorRT-LLM, and SGLang, aiming to provide a comprehensive understanding of making AI products faster, cheaper, and more scalable. AI
IMPACT Provides a deep dive into LLM inference engineering, crucial for optimizing AI product performance and cost.
RANK_REASON The article is a detailed technical handbook explaining LLM inference, not a new model release or benchmark. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →