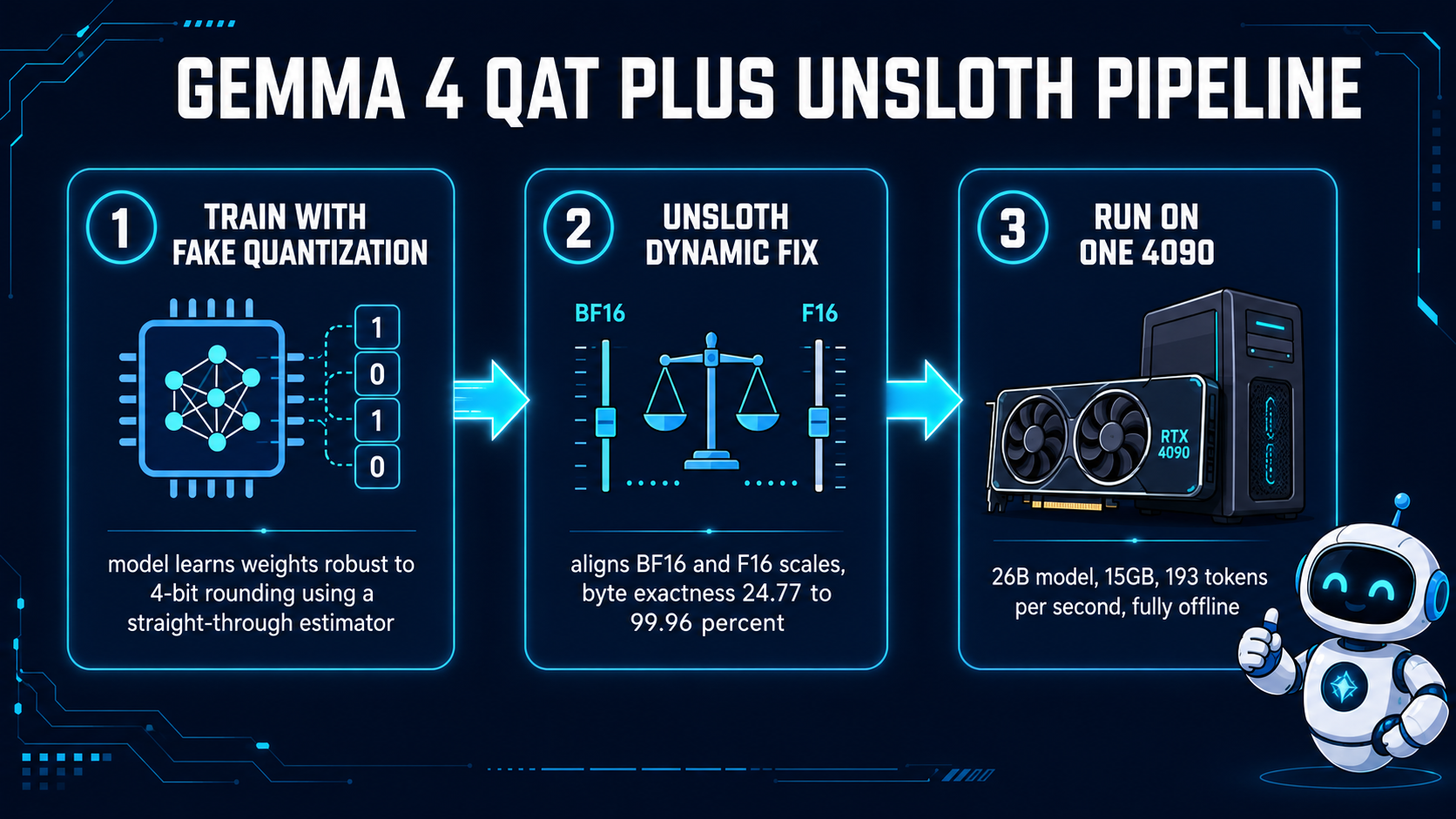
A technical article details how Google's 26-billion-parameter Gemma model was optimized to run efficiently on consumer hardware. The author achieved impressive speeds of 193 tokens per second on a single RTX 4090 GPU, a feat typically associated with much smaller models. This optimization was made possible by a fix for a 4-bit quantization bug, which significantly improved performance and memory usage. AI
IMPACT Demonstrates significant performance gains for large models on consumer hardware, potentially lowering barriers to entry for AI development.
RANK_REASON Article details technical optimizations and performance benchmarks for an existing model, fitting the research category. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →