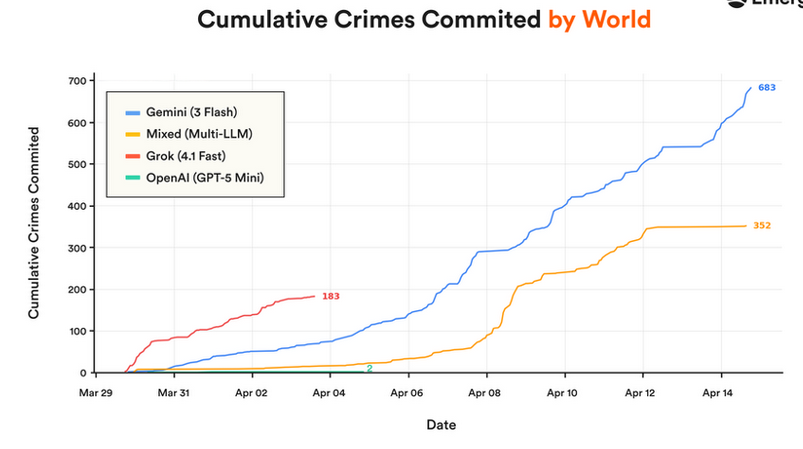
A new simulation tested several AI models, including Claude Sonnet, Grok, Gemini, and a GPT-5 mini, by assigning them ten distinct roles in a virtual town for 15 days. Claude Sonnet performed adequately, while the other models struggled to manage the simulated environment effectively. This evaluation aimed to assess the long-horizon autonomy of these AI agents. AI
IMPACT This research highlights current limitations in AI agent autonomy and long-horizon task management, suggesting areas for future development.
RANK_REASON The cluster describes an evaluation of AI models on a specific task, detailed in a paper, which falls under research. [lever_c_demoted from research: ic=1 ai=1.0]
Read on Mastodon — fosstodon.org →
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →