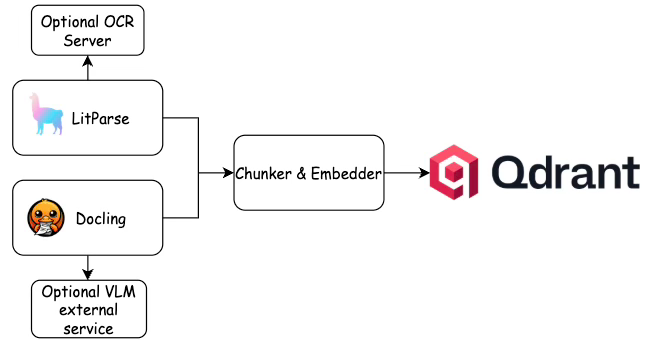
This article evaluates two open-source document parsers, LitParse from LlamaIndex and Docling from IBM Research, for their effectiveness in preparing documents for Retrieval-Augmented Generation (RAG) pipelines. The evaluation focused on a challenging 340-page technical textbook containing complex tables and code blocks, highlighting the critical but often overlooked role of document parsing in RAG system performance. The goal was to provide objective performance data on how these parsers handle difficult document structures before ingestion into vector databases like Qdrant. AI
IMPACT Accurate document parsing is crucial for effective RAG systems, impacting retrieval quality and LLM performance.
RANK_REASON The article presents an evaluation of open-source tools for a specific AI task (RAG pipeline preprocessing), which falls under research and development. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →