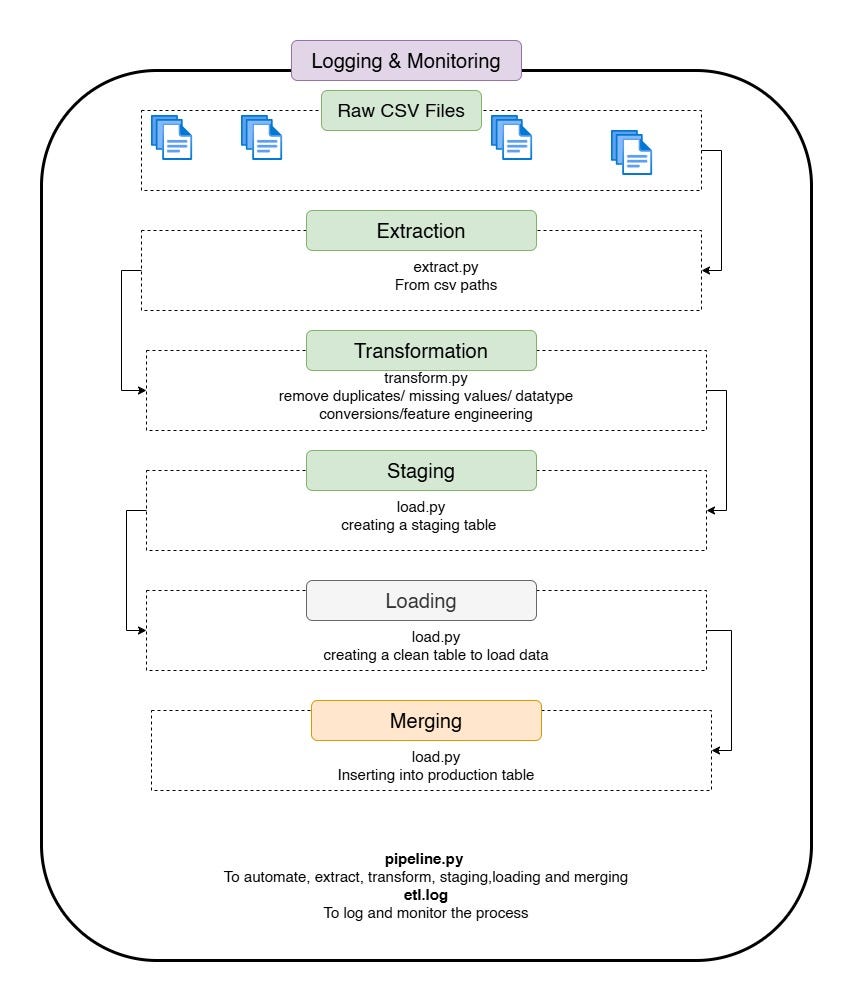
This article details the construction of a production-ready ETL pipeline designed to transfer data from CSV files into a PostgreSQL database. It covers essential data engineering practices, including data extraction using Python and Pandas, transformation for cleaning and enriching data, and loading into a staging table before final insertion. The process emphasizes scalability and reliability by incorporating techniques like bulk loading, logging, and transaction management to handle real-world data quality issues. AI
IMPACT Provides a practical guide for data engineers on building robust data pipelines, essential for feeding clean data into AI and ML models.
RANK_REASON The article describes a technical implementation of a data pipeline, which falls under research and development in data engineering practices. [lever_c_demoted from research: ic=1 ai=0.4]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →