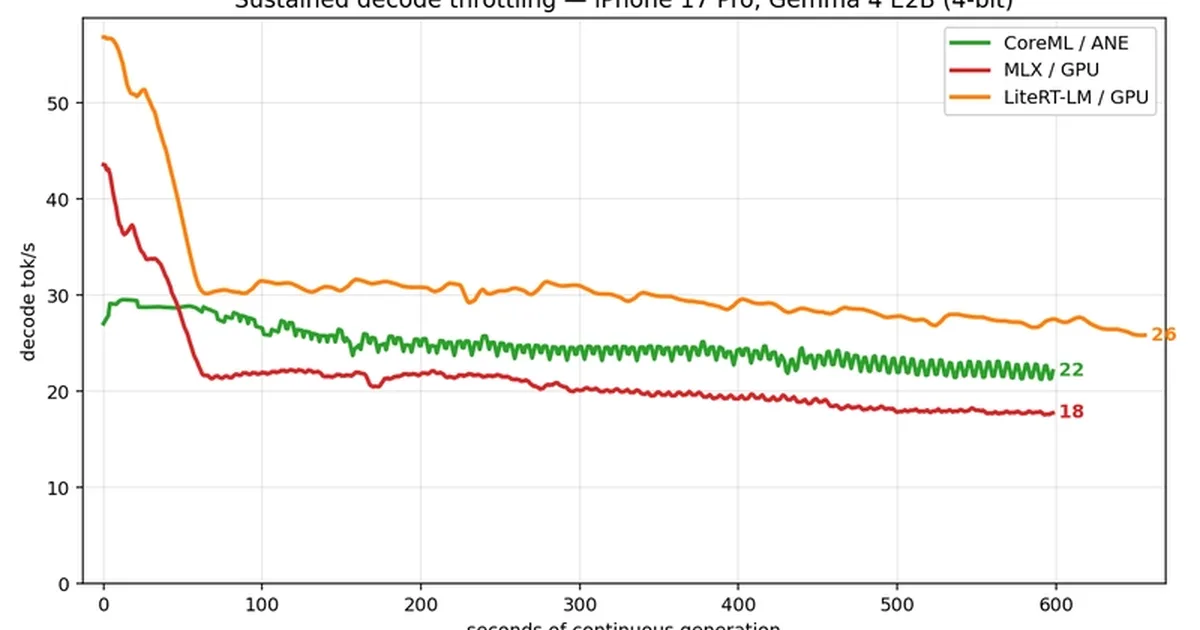
On-device LLM performance on the iPhone 17 Pro reveals that while GPUs offer superior initial generation speeds, they quickly overheat and throttle. Apple's Neural Engine, though slower to start, maintains a more consistent decode rate over extended periods due to significantly lower power consumption. This suggests that for applications requiring sustained LLM operations, the Neural Engine is the more efficient and ultimately faster choice, while GPUs are better suited for quick, burst-like interactions. AI
IMPACT Neural Engine's sustained performance advantage suggests optimized LLM deployment for mobile applications requiring long-running tasks.
RANK_REASON Benchmark analysis of LLM performance on mobile hardware. [lever_c_demoted from research: ic=1 ai=0.7]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →