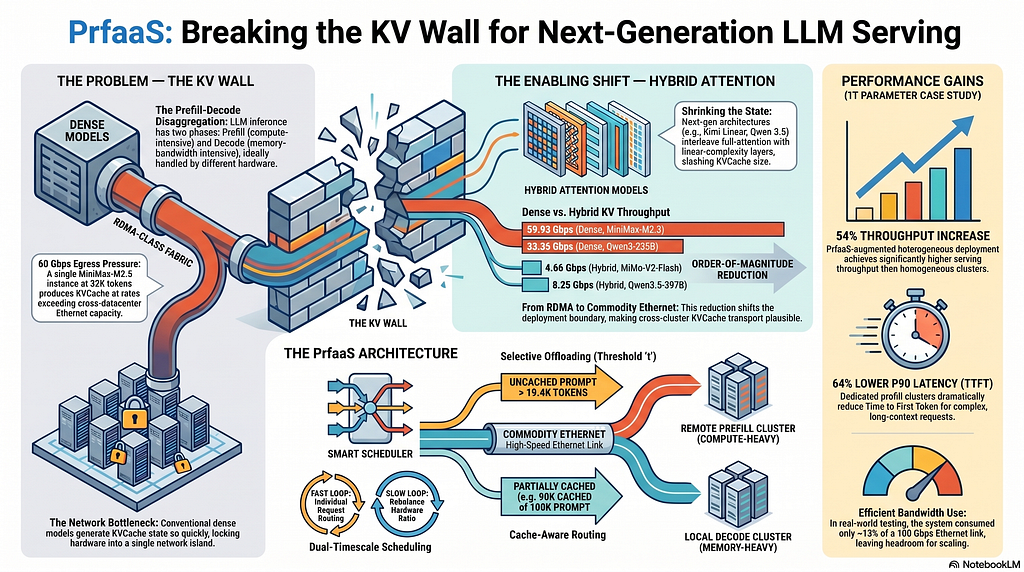
A new paper from Moonshot AI and Tsinghua University proposes a method to overcome the 'KV wall' in large language model serving. The approach, called 'Prefill-as-a-Service,' enables cross-datacenter inference by making KV caches smaller with hybrid-attention models and implementing smart routing to offload only necessary requests. This is crucial for heterogeneous hardware setups where compute-dense and bandwidth-optimized chips are not co-located. AI
IMPACT Enables more efficient LLM serving across distributed hardware, potentially reducing inference costs and latency.
RANK_REASON The cluster discusses a research paper detailing a new technical approach for LLM serving. [lever_c_demoted from research: ic=1 ai=1.0]
- Groq
- hybrid-attention models
- KV cache
- Moonshot AI
- NVIDIA
- Prefill-as-a-Service
- Transformer
- Tsinghua University
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →