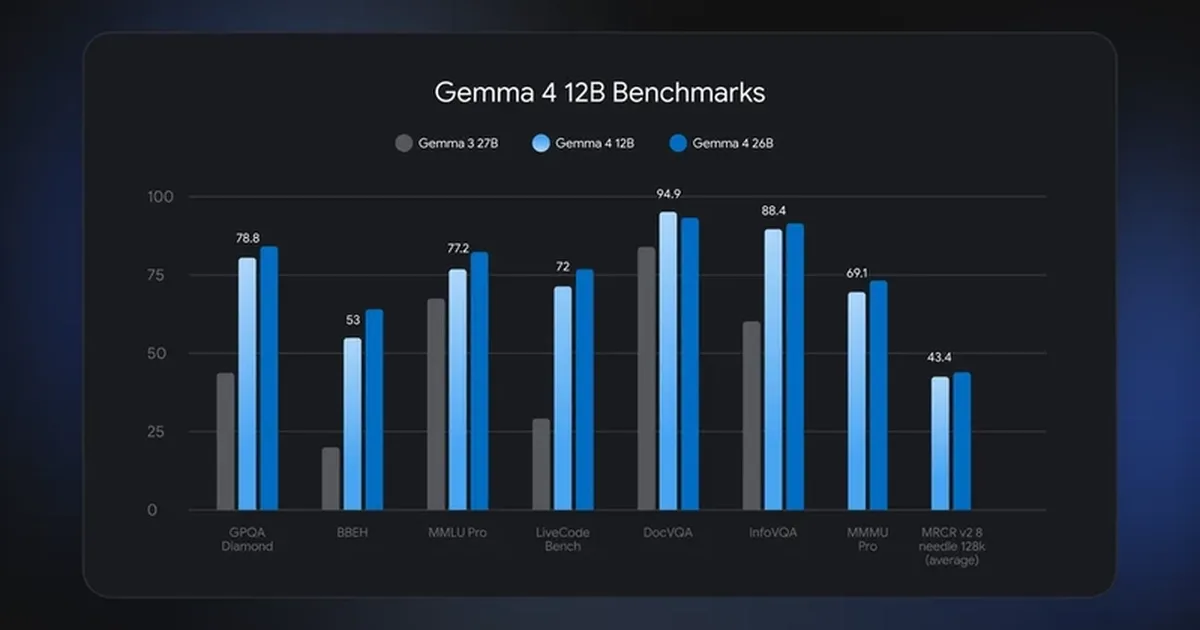
Google has released Gemma 4 12B, a multimodal model capable of processing text, images, audio, and video with a single, unified pathway. This open-weights model is designed for efficient local deployment, requiring only 16GB of memory and eliminating the need for separate vision and audio encoders. While not as powerful as larger models like the 26B or 31B variants, the 12B model offers near-comparable quality for tasks such as creative writing, coding assistance, and agentic workflows. AI
IMPACT Enables local multimodal AI applications on consumer hardware, potentially lowering barriers for developers.
RANK_REASON New multimodal model release from Google DeepMind.
- Gemma 4 12B
- Google DeepMind
- Apache 2.0
- DeepSeek V4
- Gemma 4
- gemma-4-12B-it
- MiniMax M3
- Qwen 3.7
- Gemma 4 26B
- Gemma 4 31B
- Gemma 4 E4B
AI-generated summary · Google Gemini · from 4 sources. How we write summaries →