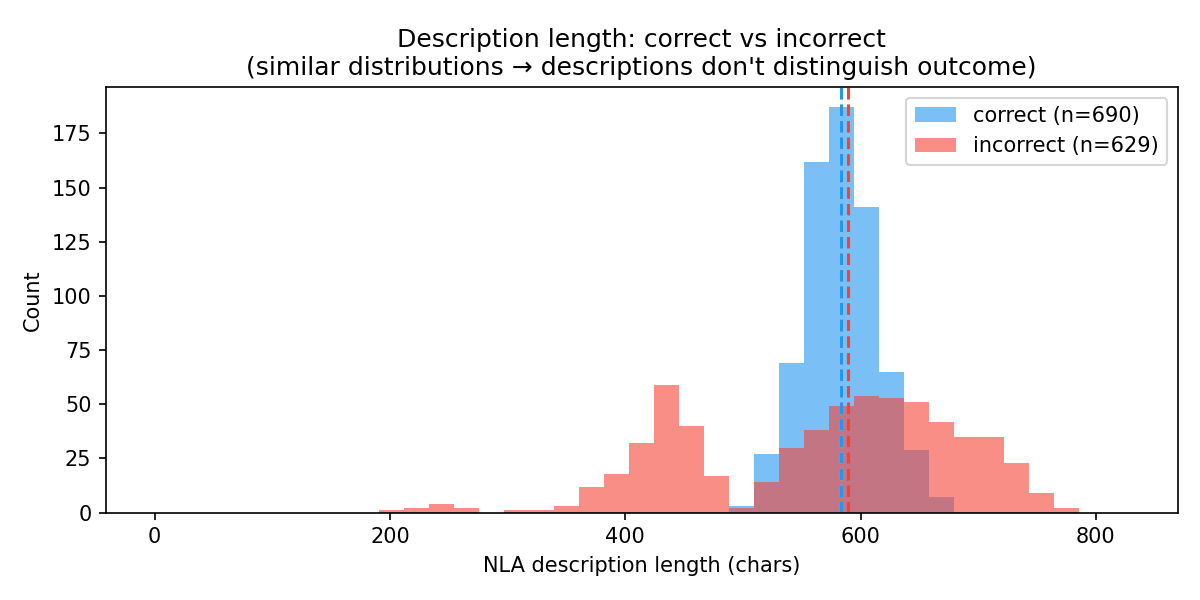
Researchers explored Natural Language Autoencoders (NLAs) to understand their relationship with model predictions, finding that the position of extraction significantly impacts whether the NLA contains the final answer. NLAs are more likely to include the correct output as the token approaches the model's final answer. Degenerate or broken NLA outputs were observed only for activations that led to incorrect model responses, suggesting that the training reward encourages models to incorporate correct answers into NLAs. AI
IMPACT Provides insights into how intermediate model representations relate to final outputs, potentially aiding interpretability research.
RANK_REASON The cluster details findings from a research paper analyzing NLA behavior. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →