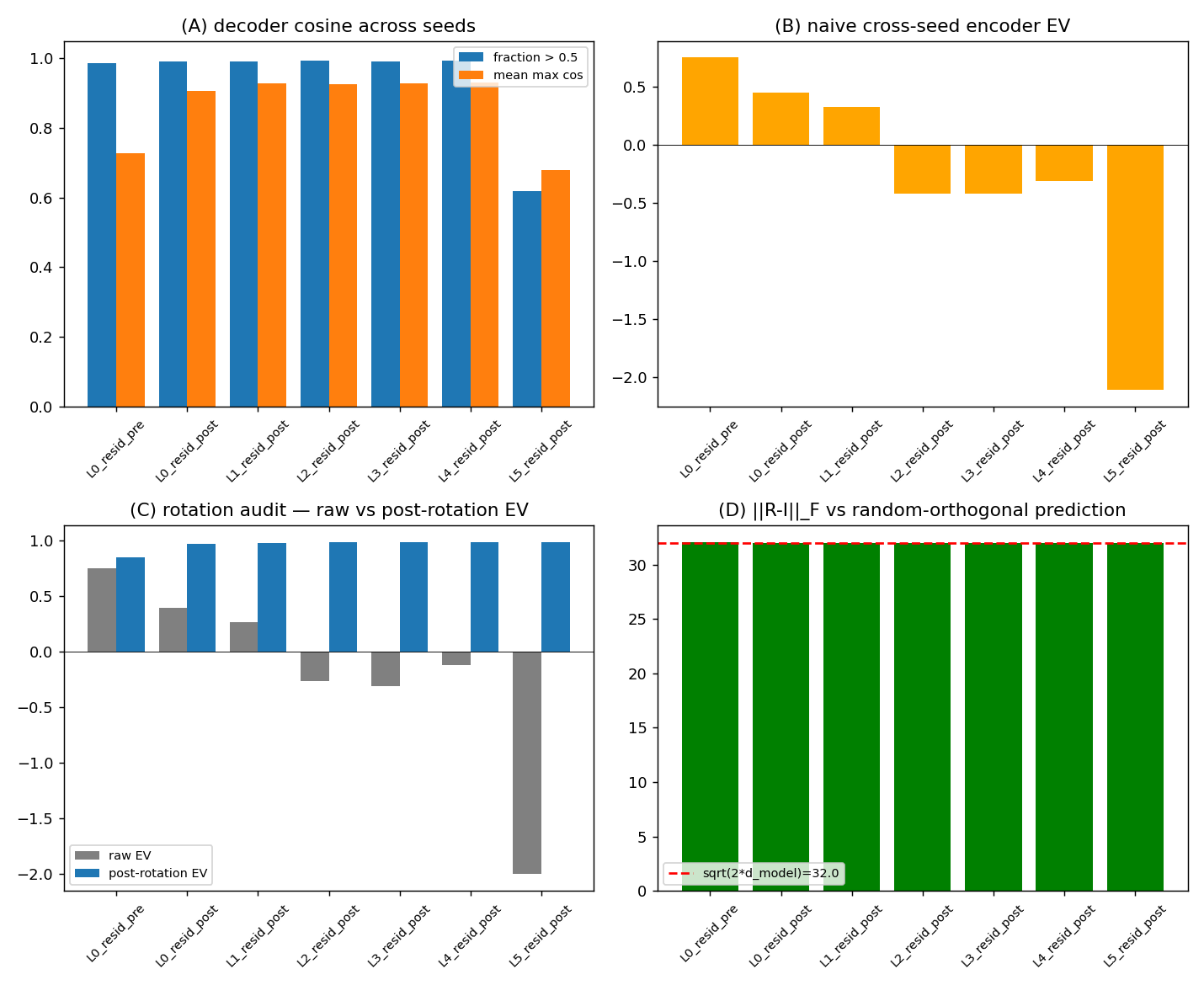
Researchers have discovered that while independently trained transformer models of the same architecture learn similar features, their internal activation representations are rotated by a random amount. This "polymorphism" means that features identified in one model are unintelligible in another without correction. Applying a Sparse Autoencoder (SAE) trained on one model to another results in catastrophic reconstruction failure, but this can be fixed with a single matrix multiplication to align the bases. AI
IMPACT Understanding internal model representations could lead to better interpretability and steerability of AI systems.
RANK_REASON Academic paper detailing a novel finding about internal model representations. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →