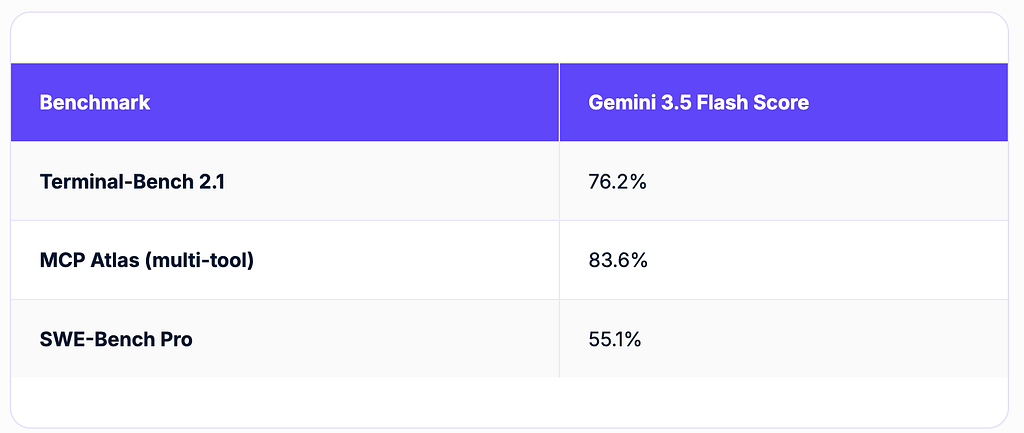
A recent comparison evaluated three AI coding agents: OpenAI's Codex (powered by GPT-5.5), Anthropic's Claude Code (using Claude Sonnet 4.6), and Google's Antigravity (with Gemini 3.5 Flash). The experiment focused on real-world engineering tasks to determine which agent performed best. GPT-5.5 excelled in terminal command execution, Claude Sonnet 4.6 led in SWE-Bench for production code tasks, and Gemini 3.5 Flash demonstrated superior multi-tool orchestration capabilities and speed. AI
IMPACT Provides comparative performance data to help developers choose the most effective AI coding agent for specific tasks.
RANK_REASON The cluster compares performance benchmarks of different AI models for coding tasks, presented in an article format. [lever_c_demoted from research: ic=1 ai=1.0]
- Anthropic
- Claude Code
- Claude Sonnet 4.6
- Codex
- Gemini 3.5 Flash
- GPT-5.5
- MCP Atlas
- OpenAI
- SWE-Bench
- Terminal-Bench 2.0
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →