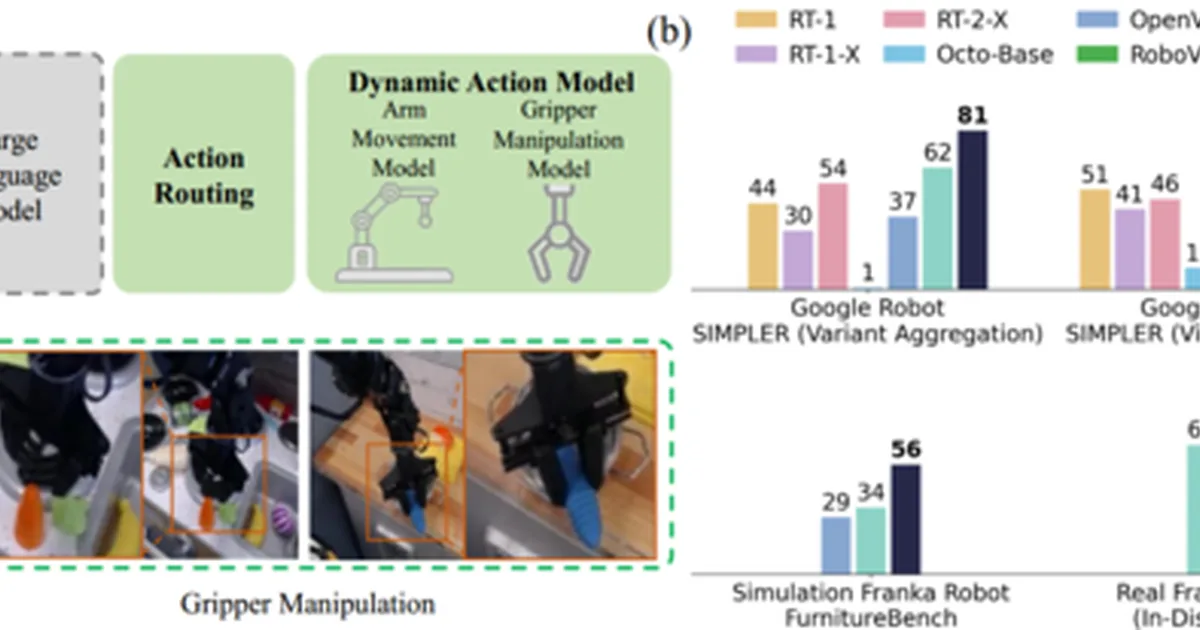
Researchers have introduced DAM-VLA, a novel Vision-Language-Action (VLA) model designed to enhance robot manipulation by decoupling arm movements from gripper actions. This approach addresses the limitations of existing models that use a single action framework for all tasks, which struggles with the distinct requirements of large-scale arm movements and precise gripper operations. DAM-VLA utilizes a dual-scale weighting mechanism and dynamic action routing to improve efficiency and accuracy, achieving state-of-the-art results on pick-and-place and furniture assembly tasks. AI
IMPACT Introduces a new VLA architecture that improves robot manipulation accuracy and generalization, potentially accelerating progress in embodied AI.
RANK_REASON This is a research paper detailing a new model architecture for robot manipulation.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →