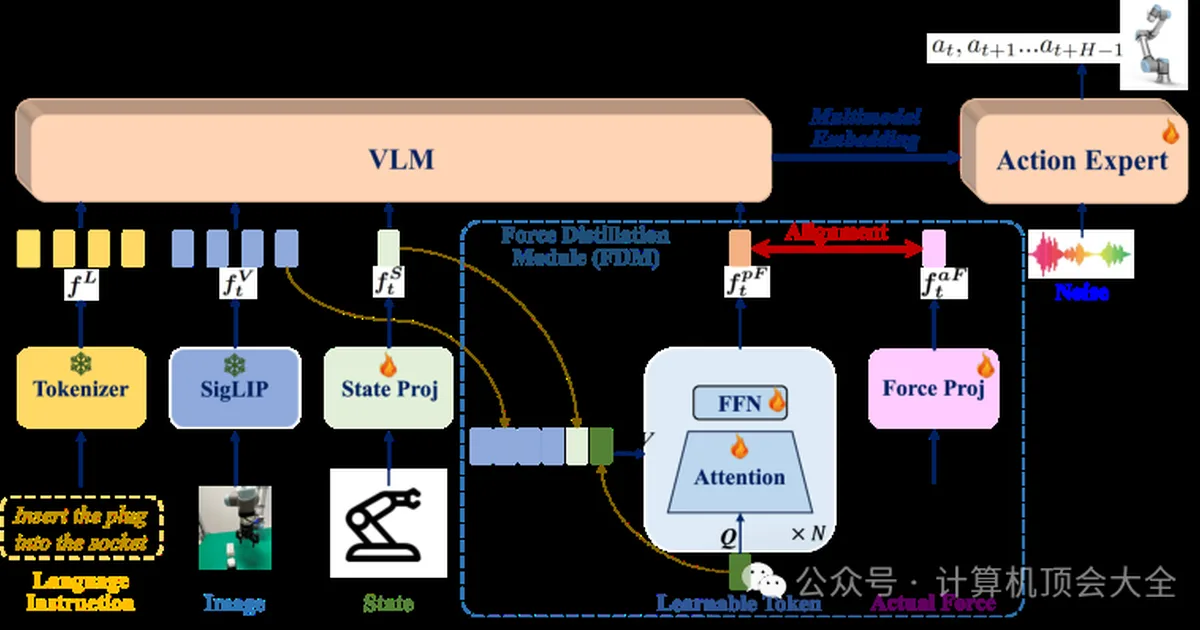
Researchers from the National University of Singapore have developed FD-VLA, a novel Vision-Language-Action (VLA) model designed to improve robotic manipulation in contact-rich tasks. Unlike previous VLA models that primarily relied on visual and linguistic cues, FD-VLA incorporates force information through a distillation mechanism. This allows the model to learn latent force representations during training and predict force cues from visual and proprioceptive data during inference, reducing reliance on physical force sensors. Experiments on a real robot platform demonstrated that FD-VLA significantly outperforms models without force awareness or those using raw force signals, highlighting the effectiveness of learned force representations for tasks like wiping whiteboards, pressing buttons, and inserting plugs. AI
IMPACT Enhances robotic manipulation capabilities by integrating force feedback, potentially improving performance in complex physical tasks.
RANK_REASON The cluster describes a new academic paper detailing a novel model for robotic manipulation. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →