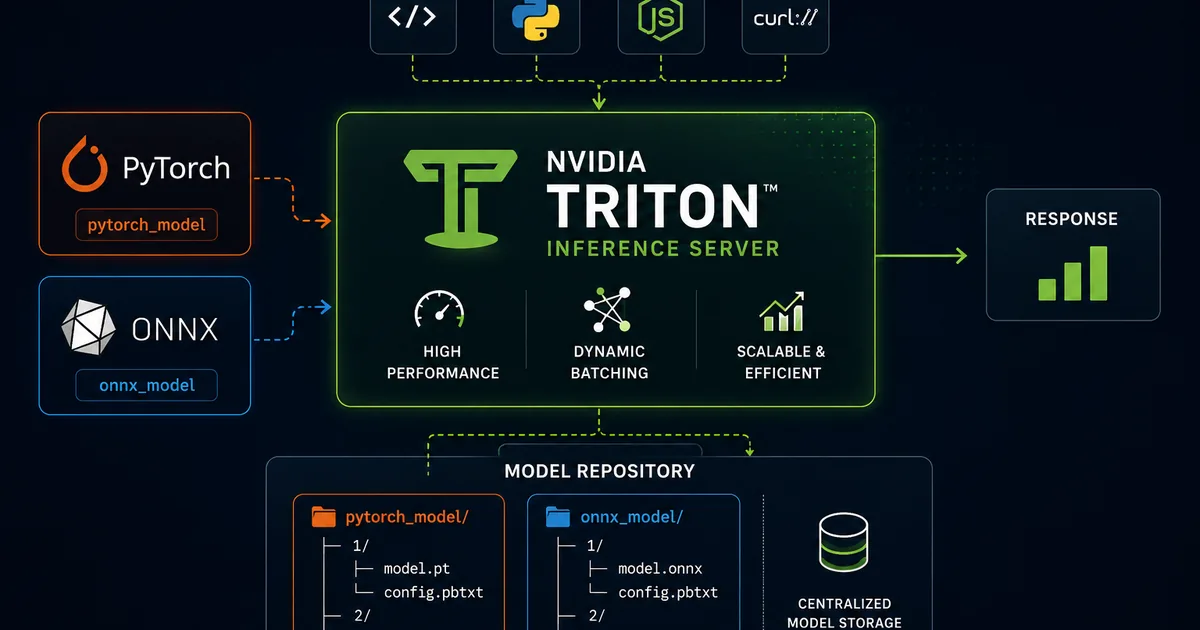
This article details how to run both PyTorch and ONNX models simultaneously on a single inference server using NVIDIA's Triton Inference Server. The process is demonstrated on a local Mac environment without requiring a GPU, highlighting the flexibility and accessibility of the setup for MLOps practices. AI
IMPACT Enables efficient deployment of diverse AI models on a single server, reducing infrastructure needs and simplifying MLOps workflows.
RANK_REASON The article describes a technical how-to guide for deploying existing models on a specific inference server, which falls under tooling.
AI-generated summary · Google Gemini · from 2 sources. How we write summaries →