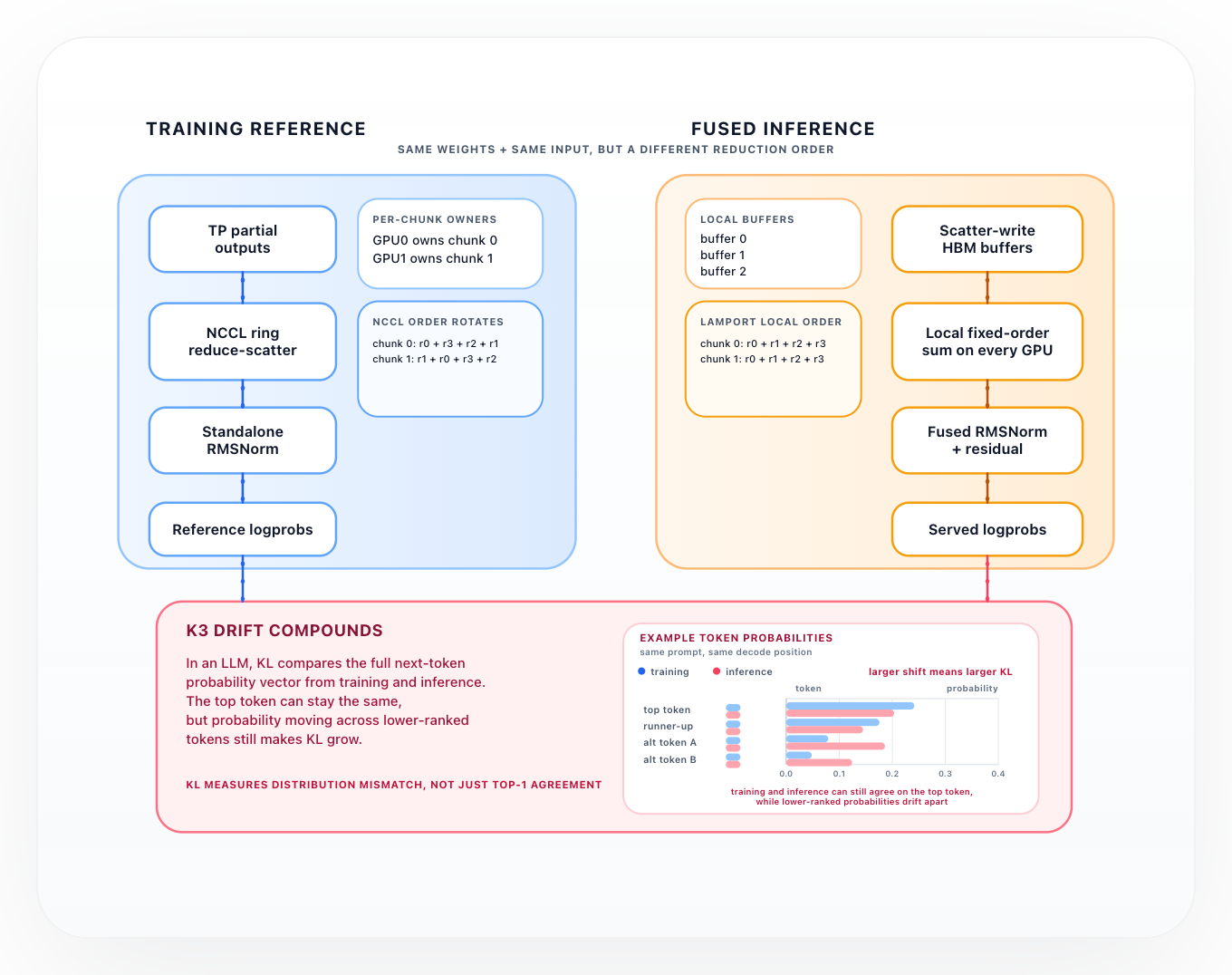
Fireworks AI has identified critical numerical parity bugs that can arise when training and serving large language models, particularly Mixture-of-Experts (MoE) architectures. These discrepancies, stemming from the non-associative nature of floating-point arithmetic and differing summation orders in distributed training versus inference, can lead to subtle but significant issues. Such drift can compromise the integrity of reinforcement learning from human feedback (RLHF) due to altered log probabilities and erode customer trust in fine-tuned models. AI
Summary written by gemini-2.5-flash-lite from 1 sources. How we write summaries →
IMPACT Highlights potential issues in LLM training and serving pipelines that could affect model performance and reliability, especially for MoE architectures.
RANK_REASON The article details technical challenges and findings related to numerical precision in LLM training and serving, which is a research-level topic. [lever_c_demoted from research: ic=1 ai=1.0]