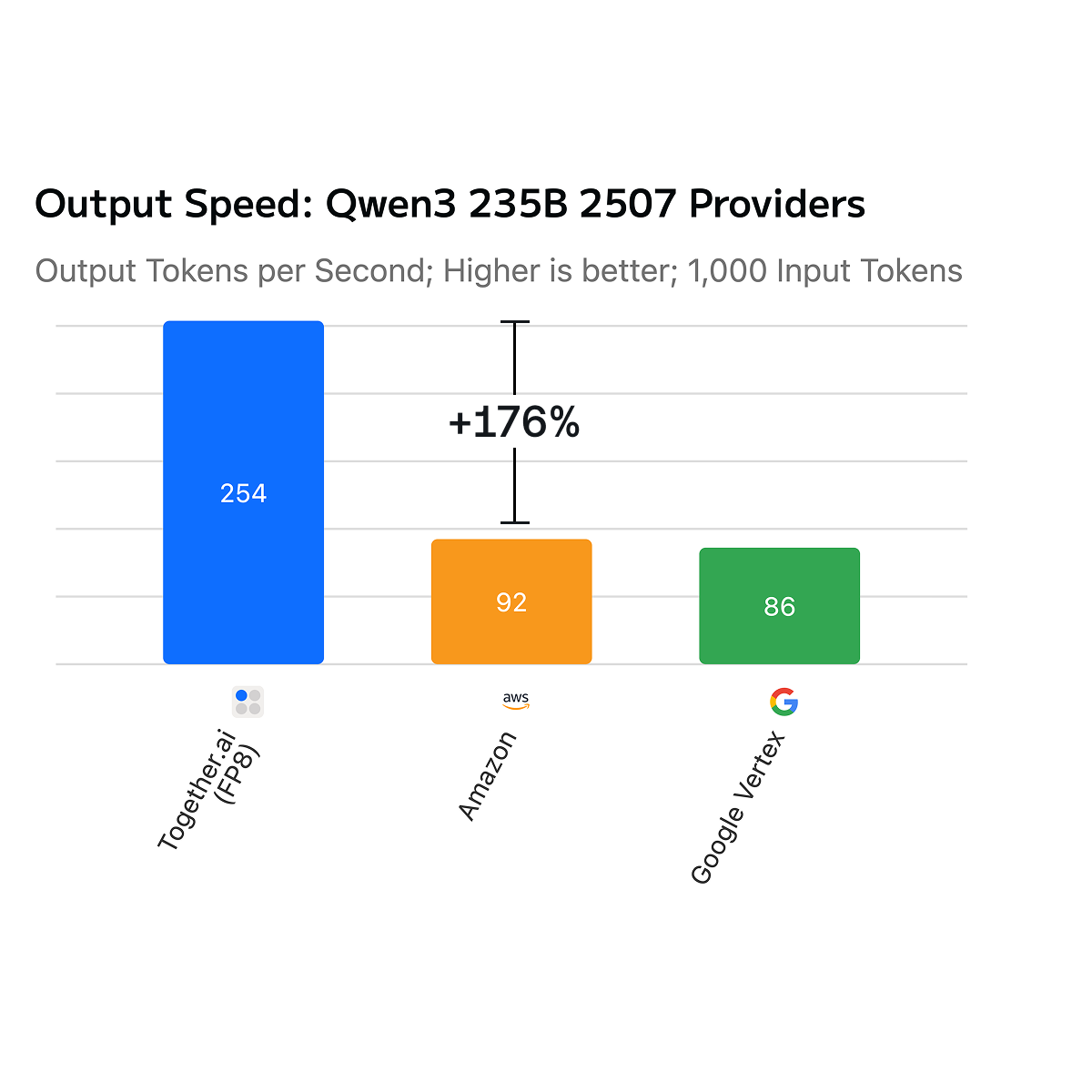
Together AI has launched a new service called Dedicated Container Inference, designed to optimize the deployment and performance of custom generative media models. This platform handles complex orchestration tasks like autoscaling, queuing, and traffic isolation, allowing teams to focus on their model logic. The service has already demonstrated significant inference speedups, with some customers experiencing up to 2.6x faster performance. Additionally, Together AI has announced advancements in their inference platform, achieving up to 2x faster serverless inference for top open-source models by leveraging next-generation GPU hardware and optimized kernels. AI
IMPACT Accelerates deployment and inference for custom and open-source AI models, potentially lowering costs and increasing accessibility for specialized AI applications.
RANK_REASON The cluster announces a new product offering and significant performance improvements for existing services from a notable AI infrastructure provider.
- Creatify
- Dedicated Container Inference
- DeepSeek-R1
- DeepSeek-V3.1
- GPT-OSS
- Hedra
- Kimi-K2
- NVIDIA Blackwell
- Qwen3
- Together AI
AI-generated summary · Google Gemini · from 3 sources. How we write summaries →