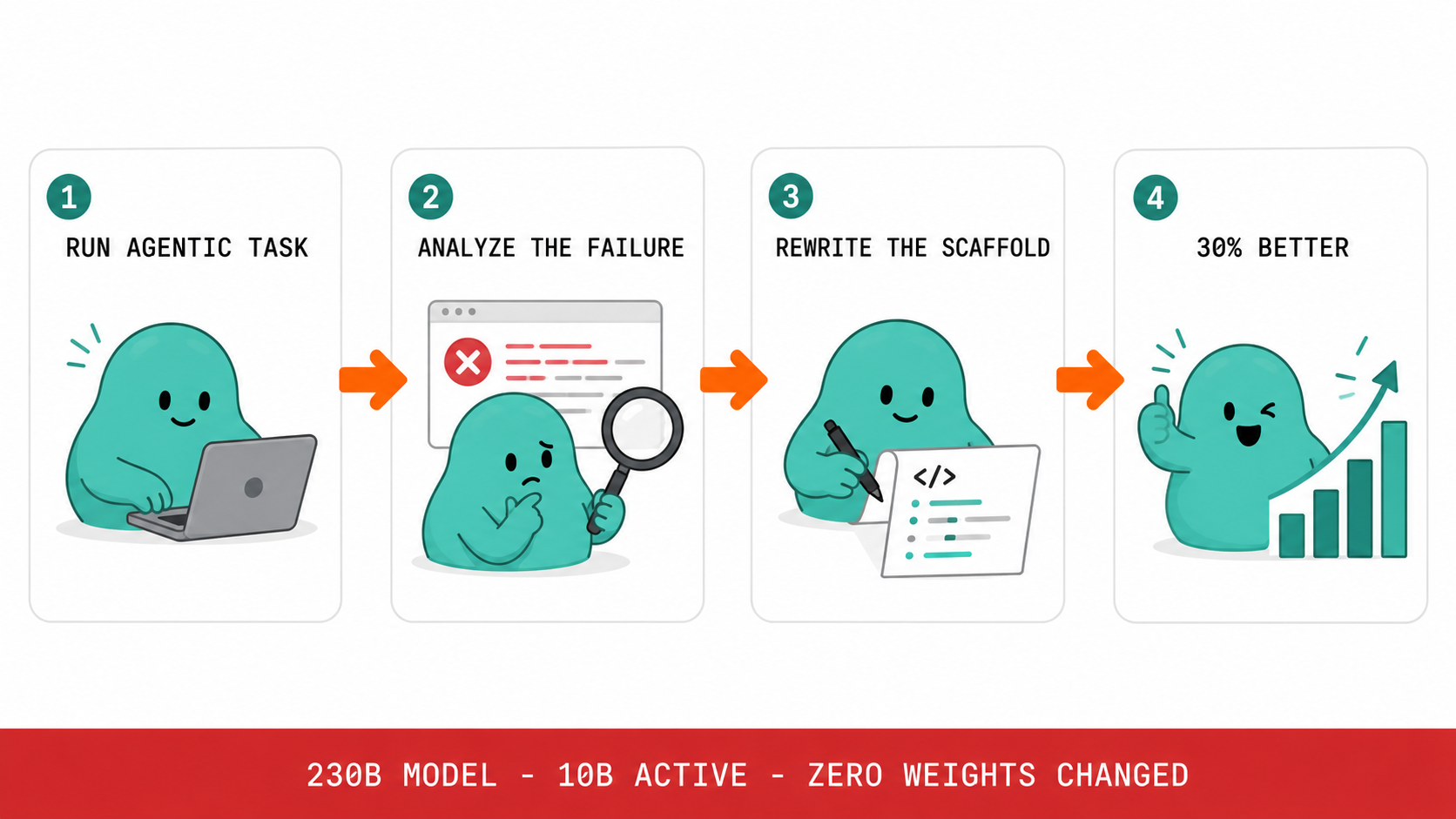
MiniMax's M2.7, a 230 billion parameter model, has demonstrated impressive capabilities in self-training and agentic coding tasks. Initial testing suggests it performs beyond expectations, challenging the notion that it would be a low-quality Mixture-of-Experts model. The model's performance indicates a significant step forward in AI development, particularly in its ability to learn and adapt autonomously. AI
Summary written by gemini-2.5-flash-lite from 1 sources. How we write summaries →
IMPACT Demonstrates advanced self-training and coding capabilities, potentially setting new benchmarks for autonomous AI development.
RANK_REASON The cluster discusses a specific model's performance on benchmarks, which falls under research. [lever_c_demoted from research: ic=1 ai=1.0]